
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に引き続き、2015年に公開された論文「Large-scale cluster management at Google with Borg」をもとにして、Googleのクラスター管理システム「Borg」を紹介します。今回は、Borgの利用効率に関するいつくかの統計データ、そして、複数のワークロードを共通のクラスター(セル)で効率的に並列実行するために必要となる、リソース分割の機能について説明します。
前回の記事でも触れたように、サーバーの利用効率を高めること、すなわち、より少数のサーバーでより多くのタスクを実行することが、タスクスケジューリングの1つの目標となります。Googleの社内で利用されるBorgの環境では、前回説明したタスクスケジューラーの機能だけではなく、次のような利用方法を採用することで、利用効率をさらに高めることに成功しています。
冒頭の論文では、これらの効果を示すいくつかのシミュレーション結果が示されています。まず、1つめの「異なる種類のワークロード」というのは、実サービスを提供する優先度の高い「prod」タスクと、バッチジョブや開発中のサービスなど優先度の低い「non-prod」タスクを同一のセルで実行するという意味です。図1は、A〜Eの5つのセルについて、non-prodのタスクを別のセルに分けた場合に、必要なサーバー数がどの程度増加するかをシミュレーションした結果になります。
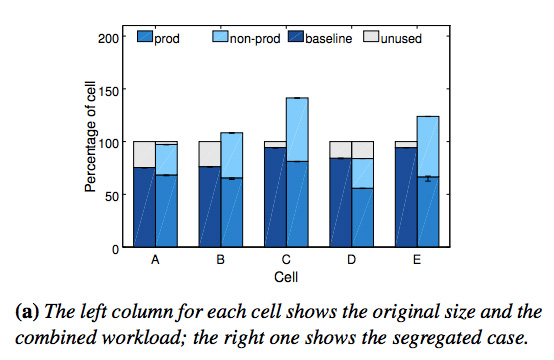
図1 ワークロードの統合によるリソース削減効果
各セルについて、2つの棒グラフがありますが、左側の「baseline」は、実際のセルに含まれる全サーバーにおける稼働率を表します。「unused」の部分は、突発的なアクセスの増加などに対応するための余剰リソースと理解できます。一方、右側の「prod」と「non-prod」は、これらを別々のセルに分けた場合に、それぞれについて必要となるサーバーの割合です。セルDを除いて、いずれも、セルを分けるとより多くのサーバーが必要になることがわかります。開発環境と本番環境でサーバーを分けるというのは、一般企業では当たり前のように行われていることですが、Googleでは、これらの環境をあえて同一のセルに統合することで、リソースの利用効率をさらにあげているわけです。
複数のユーザー/サービスのタスクを混在させるというのも、これと同様の発想です。図2は、セル内に、トータルで10TB以上、もしくは、100TB以上のメモリーを使用している「大型プロジェクト」があった場合に、これらを別のセルに分けるとどうなるかというシミュレーション結果です。
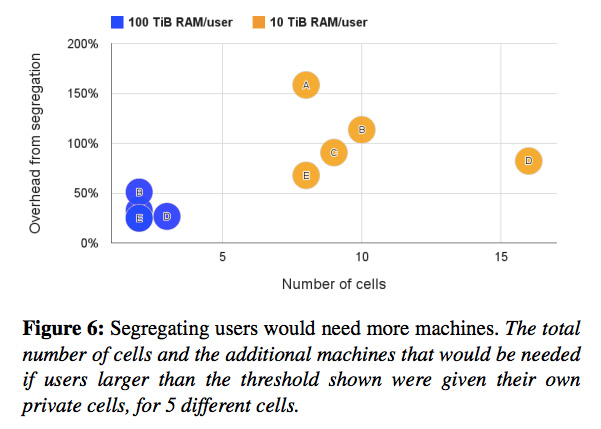
図2 大型プロジェクト(ユーザー)を別のセルに分けた場合の影響
先と同様に、A〜Eの5つのセルについての結果が示されていますが、たとえば、Dのセルについて、黄色で示されたデータを見ると、10TB以上のメモリーを使用するプロジェクト(ユーザー)が15以上もあり、これらを別のセルに分けた場合、必要なサーバー数が80%程度増加することを示しています。青色で示されたデータを見ると、別のセルに分ける基準を100TB以上のメモリー使用量とした場合でも、3つのプロジェクト(ユーザー)を別のセルに分ける必要があることがわかります。
この結果を見ると、1つのBorgのセルにおいて、複数の大規模サービスが並列稼働していることが想像できます。このように、大きなセルに複数のプロジェクトを統合することで、リソースの利用効率がより高まるという効果があります。論文の中では、1つのセルを単純に複数に分割した場合に、必要なサーバー数がどの程度増加するかを示したシミュレーション結果も記載されています。
Borgで実行されるタスクは、ジョブを投入する際の設定ファイルにより、それぞれに対するリソースの割り当て量が指定されます。CPUについては、「ミリコア」(単位時間あたり、1コアの性能を何ミリ秒割り当てるか)、メモリーとディスク容量については、「バイト」の単位で設定が可能です。一般的な仮想マシン環境では、CPUコア数、あるいは、GB単位でのメモリーやディスク容量の割り当てが行われますが、この場合、仮想マシンごとに未使用のリソースが発生して、全体として大きな無駄が発生します。前回説明したように、Borgの環境では、Linuxコンテナによるタスクの分離が行われるため、より細かな粒度でのリソース割り当てが可能になっており、これにより、ユーザーが割り当て要求したにもかかわらず実際には使用されないという、無駄なリソースの発生を低減することができます。
さらに、Borgの環境では、ユーザーが要求した割り当て量に対して、実際にセル内で確保するリソース量を少なめに見積もるという最適化が行われます。つまり、実際の使用量は、要求量よりもある程度は少なくなることを事前に勘案しているのです。図3は、CPUとメモリーについてこれらの関係を示したグラフです。
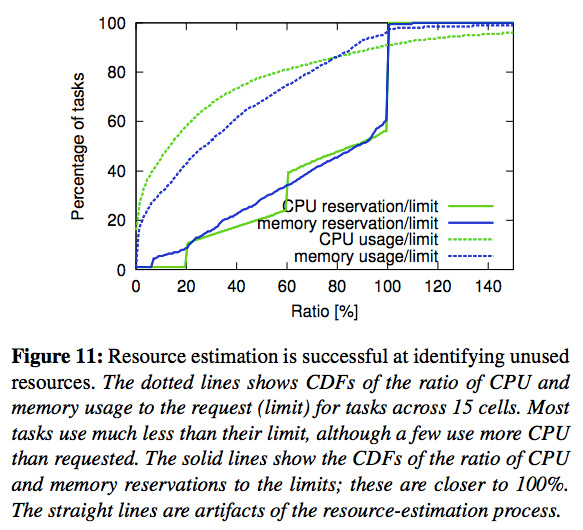
図3 リソースの割り当て要求量と実際の使用量/確保量の関係
破線のグラフは、要求量に対する実際の使用量を示しており、たとえば、横軸が80%に対して、縦軸の値が約85%になっていることから、実際の使用量が要求量の80%以下のタスクが全体の85%程度あることがわかります。一方、実線のグラフは、要求量に対する実際の確保量を同様の方式で示したものです。このような仕組みを採用した場合、時には、タスクが必要とするリソースが確保できないという事態も起こりえます。そのような際は、前回説明したように、優先度の低い「non-prod」のタスクを強制停止して、優先度の高い「prod」のタスクに割り当てるという処理が行われます。
また、エンドユーザーにサービスを提供する、レスポンスタイムが重要なタスクには、「LS(latency-sensitive)クラス」というラベルが付けられます。それぞれのタスクにリソースを割り当てる際は、LSクラスのタスクには、優先的にCPUやI/Oの処理時間が割り当てられる他、特に応答時間が重要なアプリケーションには、特定のCPUコアを専有させるといった設定も可能です。このようなリアルタイムでのリソース割り当ては、Linuxのcgroupsの機能によって行われます。
今回は、論文「Large-scale cluster management at Google with Borg」をもとにして、Googleのデータセンターにおけるアプリケーション実行基盤の標準環境である「Borg」について、サーバーの利用効率に関するいくつかのシミュレーション結果を紹介しました。さまざまなワークロードを統合した大規模なクラスター環境に加えて、Linuxコンテナを利用した、より細かな粒度でのリソース分割が全体的な利用効率の向上に寄与していることがわかります。
次回は、Google社内で利用されているデータ検索機能、一般に「データレイク」と呼ばれる機能を提供するシステムを紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































