
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2016年に公開された論文「Goods: Organizing Google's Datasets」をもとにして、Bigtable、Spanner、GFSと言った、Google社内のデータストアを横断的に検索可能にするツール「Goods(Google Dataset Search)」を紹介していきます。最近、複数のデータストアにまたがった情報を横断的に検索・活用する手法として、「データレイク」という考え方を耳にするようになりました。これは、260億件という膨大な数のデータセットに対してデータレイクの仕組みを実現した、Googleの社内事例と言えるでしょう。
Googleの社内には、ソフトウェアエンジニアが開発中に使用するファイルシステム(Google Filesystem)やデータ分析に利用するデータベース(Spanner)など、さまざまなデータストアがあります。これらのデータストアに含まれるデータセットをカタログ化して検索可能にすることが、Goodsの大きな目的です。具体的には、図1のような情報をカタログ化しています。

図1 Goodsのカタログ情報に含まれるメタデータ(論文より抜粋)
該当のデータセットを作成したチーム/ユーザーの情報に加えて、データセット間の依存関係やデータのスキーマなどの情報が一定のルールで抽出されるようになっています。これにより、あるプロジェクトのメンバーは、自身のプロジェクトのジョブが生成するデータが他のプロジェクトからどのように利用されているのか、あるいは、自分が必要とする他のプロジェクトのデータがどのような状態にあるのかと言った情報を確認することが可能になります。つまり、単純なデータの検索だけではなく、自身のプロジェクトに関わるデータセットの全体像を把握するためのツールがGoodsなのです。
図2は、このようなGoodsの役割をまとめた図になります。図の最下段がデータソースで、中段はこれらから収集したカタログ情報、そして、上段が具体的な利用用途となります。検索機能の他に、データセットのダッシュボード、あるいは、データセットの依存関係(Provenance)のビジュアライゼーションツールなどが用意されています。
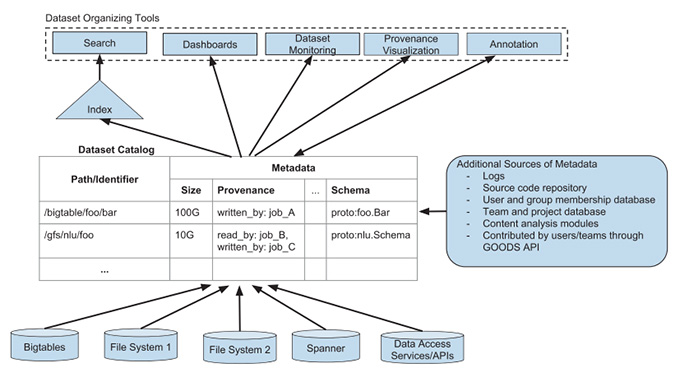
図2 Goodsの全体像(論文より抜粋)
図2の右上にある「Annotation」というのは、ユーザー自身がデータセットに対する説明を追記できる仕組みです。他のプロジェクトから利用してもらうデータセットについて、具体的な利用方法や注意点を記述することができます。
Goodsを実装する際の最大の課題は、対象となるデータセットの総量でした。検索対象とするのは、すべてのユーザーにリード権限が設定されたデータセットのみですが、それでも、図3の表に示すような大きな規模となります。全体で260億件のデータセットがあり、さらに、毎日、16億件のデータセットが追加・削除されるのです。これらのデータセットをすべてクローリングして、カタログ情報を個別に抽出した場合、数千台のサーバーを用いても1年近くの日数がかかるという見積もりになります。
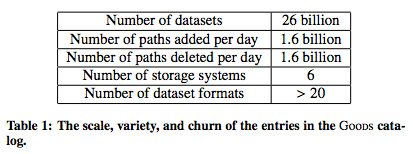
図3 Goodsが取り扱うデータセットの規模(論文より抜粋)
この問題に対応するために採用されたのが、データセットのクラスタリングです。たとえば、日次のバッチジョブが生成するデータセットの場合、日付ごとに異なるデータセットが生成されますが、これらすべてから個別にカタログ情報を抽出する必要はありません。類似の情報を含むデータセットをクラスターにまとめた上で、各クラスターからは、いくつかのデータセットをサンプリングして、それらからカタログ情報を生成します。クラスター内の他のデータセットには、これと同じカタログ情報をコピーしていきます。
図4は、ファイルシステム上のデータについて、サンプリングを行う例を簡単化して記述したものです。データファイルのパス名から、日付/バージョンの異なる同一ジョブの出力ファイルを特定して、下の2つのファイルについて、データのスキーマ(Protocol Bufferのフォーマット)を検出しています。これをこのクラスター全体のスキーマとして設定した上で、クラスター内の他のファイルについては、同じスキーマ情報をコピーするという動作になります。
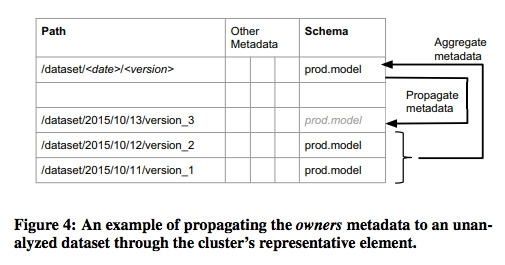
図4 クラスター内でのサンプリング処理の例(論文より抜粋)
図5は、このようにして発見されたクラスターの分布です。横軸は、クラスターに含まれるデータセットの数で、縦軸は、そのようなサイズのクラスターが何個あるかを示します。中には、10M(一千万件)ものデータセットを含むクラスターがあり、この処理によって、実際にカタログ情報を抽出するファイルの数が大幅に削減されることがわかります。
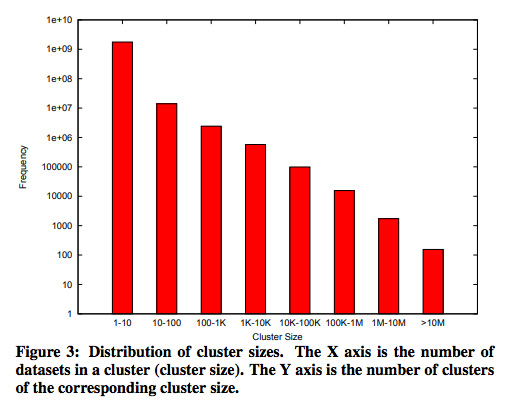
図5 データセットのクラスター分布(論文より抜粋)
今回は、論文「Goods: Organizing Google's Datasets」をもとにして、Googleの社内横断的なデータセット検索システム「Goods」の概要を紹介しました。データセットのカタログ情報を抽出すると言っても、Google社内全体となると相当な規模になることがわかります。次回は、データセットの依存関係やスキーマ情報など、具体的なカタログ情報の抽出方法、あるいは、カタログ情報を生成するバッチジョブの管理手法など、より技術的な詳細を説明したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































