これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、2016年に公開された論文「Deep Neural Networks for YouTube Recommendations」をもとにして、ビデオストリーミングサービス(YouTube)のレコメンデーションシステムを支える機械学習のアーキテクチャーを紹介します(図1)。大規模なコンシューマーサービスで用いられる仕組みのため、機械学習を専門としない方にも興味がわく分野ではないでしょうか。一般の方にも理解しやすいように、丁寧に解説していきたいと思います。
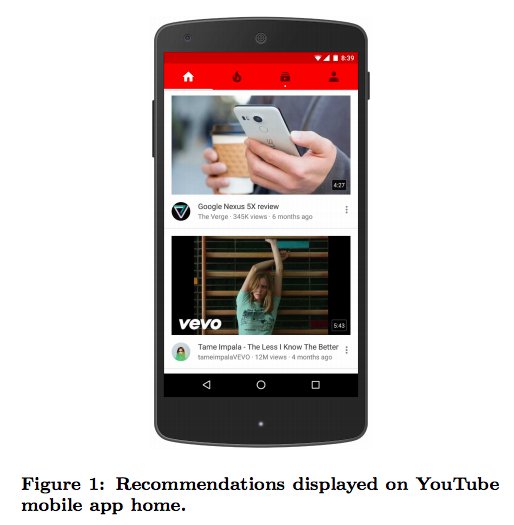
図1 モバイルアプリに表示されたレコメンデーション結果の例(論文より抜粋)
この論文では、YouTubeのレコメンデーションシステムを構築するにあたり、特に大きな課題となった点を「スケール」「鮮度」「ノイズ」という3つのキーワードで紹介しています。まず、スケールというのは、レコメンデーション対象のコンテンツの量です。協調フィルタリングなど、既存のレコメンデーションのアルゴリズムは、データ量が増えると処理が難しくなるという特性があり、YouTubeのコンテンツ量には適さないという問題がありました。次に、「鮮度」は、コンテンツの更新頻度です。YouTubeのプラットフォームでは、数秒の間にも数時間分のコンテンツが追加されていきます。昔からある定番のコンテンツと新規コンテンツ、これらをバランスよくレコメンドする仕組みが必要となります。最後に、「ノイズ」というのは、ユーザーの満足度を知るためのデータの性質です。レコメンドの結果にユーザーが満足したかどうかを直接的に知るデータは、ほとんどありません。したがって、さまざまなノイズを含んだ学習データから適切に学習ができる機械学習モデルが必要となります。
これらの課題を克服するシステムを作るためにさまざまな実験を重ねた結果、すべてのコンテンツから、数百のレコメンド候補を選び出す「候補選択モデル」と、そこからさらに、ユーザーの嗜好に応じてランク付けする「ランキングモデル」を組み合わせるという仕組みが作られました。図2はその概要図で、前段の「Candidate Generation」の部分が候補選択モデル、後段の「ranking」の部分がランキングモデルにあたります。
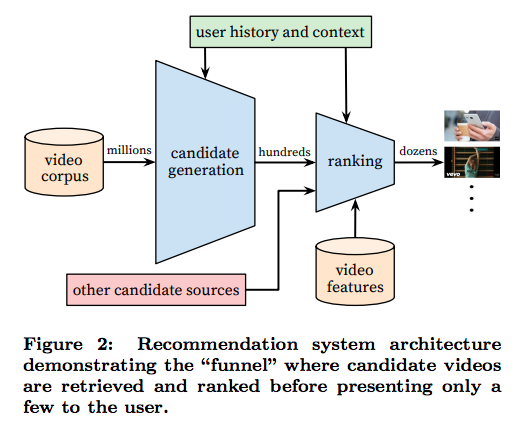
図2 レコメンデーションシステムの全体像(論文より抜粋)
それでは、候補選択モデルとランキングモデルには、どのような違いがあるのでしょうか? まず、候補選択モデルの方は、膨大なコンテンツが検索対象になります。そのため、1つひとつのコンテンツに対して個別に予測をするという手法は、現実的ではありません。たとえば、個々のコンテンツに対して、「このユーザーが次にそのコンテンツを見る確率」を予測するモデルを作ったとします。この場合、すべてのコンテンツに対して確率を計算した後、そこから確率の高いものを選ぶという処理が必要になりますが、これでは、検索に膨大な時間がかかります。
そこで、候補選択モデルでは、ユーザーの特徴と個々のコンテンツを同じ空間のベクトルで表現しておき、ユーザーとコンテンツのベクトルが近いほど、「そのユーザーが次に見る可能性が高いコンテンツ」となるようにこれらの表現を学習します。図3に示すように、あるユーザーをあらわすベクトルのまわりにあるコンテンツが、このユーザーが次に見る可能性が高いコンテンツになります。(厳密には、ユーザーとコンテンツそれぞのベクトルの内積で判定しますが、ここでは簡単に、ベクトルの距離で説明しています。)
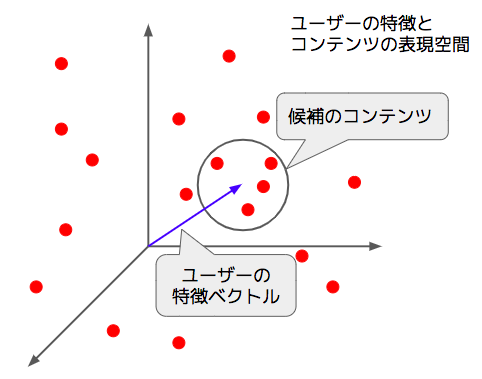
図3 ベクトル表現による候補選択の仕組み
なお、ここで言う「ユーザーの特徴」は、そのユーザーのこれまでの視聴履歴とキーワード検索履歴などを表します。これらの履歴情報は動的に変化していきますので、レコメンデーションが必要なタイミングで、該当ユーザーの履歴に対応するベクトルを計算して、そのベクトルのまわりにあるコンテンツを集めると、これが、レコメンド対象候補ということになります。
もう一方のランキングモデルは、数百までに絞り込まれた対象コンテンツについて、個々に予測処理を行います。具体的には、該当ユーザーが「そのコンテンツを視聴する時間」を予測して、この時間が長いものほど上位のレコメンド対象とします。Webコンテンツのレコメンデーションでは、「該当コンテンツのリンクをクリックする確率」を予測するという手法もよく用いられますが、ここでは、「そのコンテンツをクリックして視聴を始める確率」ではなく、「そのコンテンツを何分間見続けるか」という時間を予測しています。これにより、クリックしてもすぐに見るのをやめてしまうコンテンツ(「Clickbait/クリックベイト」と呼ばれる、過激なタイトルなどでクリックを煽るコンテンツ)がレコメンドされることを防いでいます。
今回は、2016年に公開された論文「Deep Neural Networks for YouTube Recommendations」をもとにして、YouTubeのレコメンデーションシステムの概要を紹介しました。一般的なレコメンデーション・アルゴリズムをよくご存知の方であれば、図3に示した候補選択の仕組みは、協調フィルタリングと同じ考え方と気づいたかもしれません。ただし、この候補選択モデルでは、ユーザーの特徴ベクトルの計算にディープニューラルネットワークを用いるという特徴があります。次回は、このあたりの詳細を続けて解説したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































