
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に引き続き、2016年に公開された論文「Deep Neural Networks for YouTube Recommendations」をもとにして、ビデオストリーミングサービス(YouTube)のレコメンデーションシステムを支える機械学習のアーキテクチャーを紹介します。前回の図2に示したように、このシステムでは、「候補選択モデル」と「ランキングモデル」を組み合わせた仕組みが用いられています。今回は、候補選択モデルの部分について、その仕組みを少し掘り下げて解説したいと思います。
前回の最後に少し触れたように、候補選択モデルの仕組みは、レコメンデーションのアルゴリズムとして有名な「協調フィルタリング」に類似した部分があります。そこでまず、協調フィルタリングの仕組みを簡単に復習しましょう。協調フィルタリングでは、それぞれのユーザーとレコメンデーション対象のアイテム群を同一空間のベクトルにマッピングします。このマッピングを適切に学習することで、ユーザーのベクトルとアイテムのベクトルの内積が大きいほど、ユーザーとアイテムの相性が良い(ユーザーがアイテムを気に入る可能性が高い)という状況を作り出します(図1)。
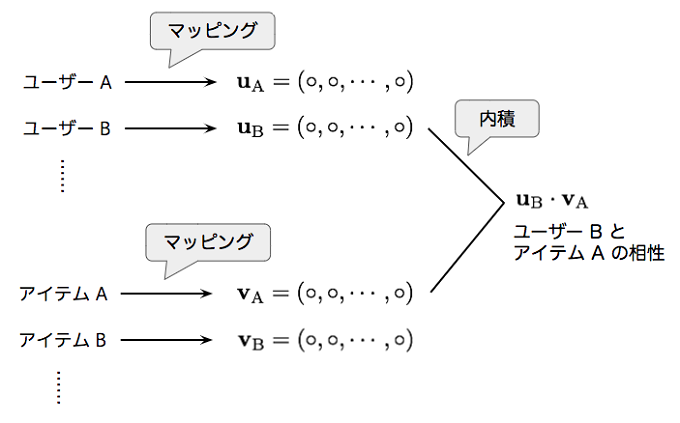
図1 協調フィルタリングによる学習
これができれば、特定のユーザーに対して、すべてのアイテムの中から「相性のよいアイテムトップ・テン(=お勧めアイテムトップ・テン)」と言ったリストを生成することができます。特定のユーザーに対応するベクトルについて、すべてのアイテムのベクトルと内積を計算した後に、内積の値が大きい順にアイテムをソートすればよいわけです。すべてのアイテムとの内積を計算するのは時間がかかりますが、実際には、内積が大きくなるアイテムを効率的に検索するアルゴリズムが知られています。アイテム数が膨大な場合は、そのような検索ライブラリを活用することになります。
ここで重要になるのが、このようなマッピングを学習する方法です。協調フィルタリングの場合は、各ユーザーとアイテムについて、対応するベクトルを個別に割り当てておき、それぞれのベクトルの成分を最適化していきます。具体的には、これまでのアイテム購入履歴やアイテム評価データ(アンケートデータ)などを教師データとして、学習後のモデル(ベクトルの内積)による評価と、実際の評価ができるだけ一致するように学習を行います。
しかしながら、協調フィルタリングの場合、各ユーザーの既存の評価データのみで学習が行われるため、ユーザーのプロファイル情報など、その他の情報を予測に活用できないという制限があります。これまで評価を登録したことのないユーザーであれば、類似のプロファイルを持ったユーザーの評価を参照するなどの手法が考えられますが、協調フィルタリングの仕組みだけでは、このような情報を取り込むことはできないのです。
協調フィルタリングの仕組みと、その課題が理解できたところで、実際の「候補選択モデル」の説明に移ります。先に説明した協調フィルタリングとの違いは、ユーザーに対応するベクトルを個別に割り当てるのではなく、ニューラルネットワークを介して計算するところにあります。具体的なネットワークの構造は、図2のようになります。
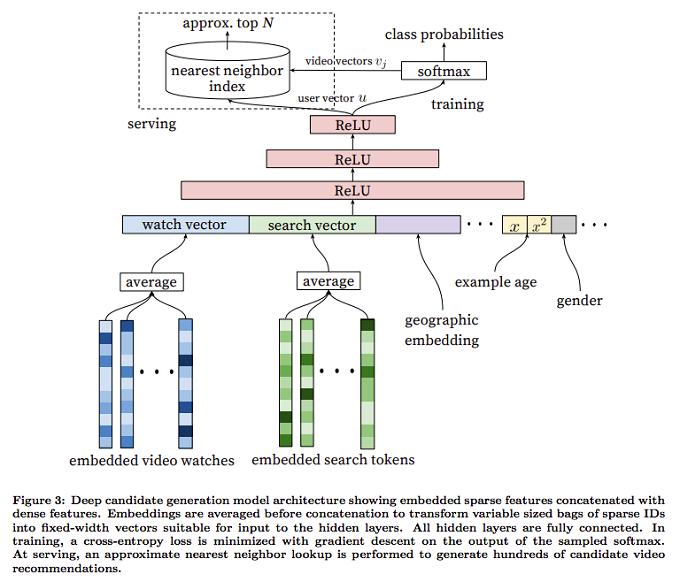
図2 「候補選択モデル」のアーキテクチャー(論文より抜粋)
ここでは、ユーザーのプロファイル情報に加えて、これまでに見た動画の履歴、および、検索キーワードの一覧が入力データとなります。これにより、既存の評価データ以外の情報が活用できないという、協調フィルタリングの課題を解決しています。動画、および、検索キーワードについては、「埋め込み表現」の手法を用いています。これは、動画IDや個々のキーワードを高次元のベクトルで表現するものですが、ここでは、過去に見た一定数の動画、あるいは、一定数の検索キーワードついて、それらを表現するベクトルの平均値を取ったものをニューラルネットワークへの入力とします。単純に平均を取るというのは乱暴な処理にも思われますが、論文の中では、自然言語処理における「continuous bag of words」という類似の処理から着想を得たと説明されています。また、埋め込み表現そのものは、次に説明するモデルの学習処理の中で、他のパラメーターと同時に学習を行います。
そして、実際の学習方法ですが、ここでは、ユーザーが実際に視聴した動画を正解ラベルとして用います。しかしながら、予測対象のコンテンツ数が膨大なため、正解データだけを用いた場合、学習に膨大な時間がかかる恐れがあります。つまり、「どの動画を視聴したか」という情報だけでは、効率的にモデルを学習するには、情報量が不十分な可能性があるのです。そこで、このモデルの学習では、「不正解データ」、つまり、モデルに入力する特徴量(動画の視聴履歴など)に対して、その直後に「視聴しなかった動画」をサンプリングするという手法を適用しました。具体的には、正解データに対する確率を大きくすると同時に、その他の不正解データに対する確率を小さくするように学習を行います。1つの正解データに対して、数千の不正解データをサンプリングすることで、学習速度が100倍以上になったことが論文の中で説明されています。
この他には、それぞれの正解/不正解データに時刻情報を付与するというテクニックも用いられています。まずはじめに、「現時点から見て、何日前の学習データなのか」という情報をモデルに入力する特徴量に加えます。これにより、予測処理時は、「○日前であれば、このユーザーが次に見る動画は何か?」という予測が可能になります。実際に予測したいのは、0日前、つまり、現時点で次に見る動画だけですので、特に有用な機能には思えませんが、これには重要に意味があります。時刻情報を付与せずに学習した場合、過去、一時的に爆発的な人気を得た動画がいつまでもレコメンドされ続けることになります。時刻情報を付与することで、古いデータの影響を相対的に落とすことが可能になるというわけです。これは、コンテンツそのものが古いかどうかではなく、「あるユーザーがその動画を見た」という情報の鮮度を見ていることになります。したがって、古いコンテンツであっても、現在もよく視聴されているものは、レコメンデーションの対象となります。
今回は、2016年に公開された論文「Deep Neural Networks for YouTube Recommendations」をもとにして、YouTubeのレコメンデーションシステム、特に「候補選択モデル」の部分を説明しました。次回は、もう一つのパートである「ランキングモデル」について解説を行います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































