これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に引き続き、2016年に公開された論文「Deep Neural Networks for YouTube Recommendations」をもとにして、ビデオストリーミングサービス(YouTube)のレコメンデーションシステムを支える機械学習のアーキテクチャーを紹介します。「候補選択モデル」と「ランキングモデル」の組み合わせからなるこのシステムについて、今回は「ランキングモデル」の仕組みを解説します。
ランキングモデルの解説に入る前に、2つのモデルの役割を復習しておきましょう。第48回で説明したように、すべてのビデオコンテンツという膨大なデータに対して、高速、かつ、正確にレコメンド対象を選択するというのは簡単なことではありません。このシステムでは、ユーザーが直近に視聴した一定数の動画、そして、同じく一定数の直近の検索キーワードという限定的な情報をもとにして、まずは、数百のレコメンド候補を選択します。これが「候補選択モデル」の役割です。
今回説明する「ランキングモデル」では、その後、より多くの種類の情報を用いて、最終的なレコメンド対象動画を決定します。ここでは、動画を視聴するプラットフォーム(動画を閲覧するアプリやホームページの種類)に固有の情報も利用することが論文の中で触れられています。たとえば、動画の内容がユーザーの好みにあっていたとしても、該当プラットフォームで表示されるサムネイルの選択によって、それをクリックする確率が下がるような場合も考えられます。このように、動画の内容だけではなく、動画とユーザーを紐付けるさまざまな情報を用いることで、それぞれのユーザーが「実際に視聴する動画」をより高い精度で予測しようというわけです。
ランキングモデルでは、数百種類のデータが予測のためのデータ、機械学習の用語で言う「特徴量」として用いられます。約半数が数値型のデータで、残りの半数がカテゴリー型のデータになります。候補選択モデルでも用いた、視聴した動画の履歴、あるいは、検索キーワードなどは、カテゴリー型のデータになります。これらのデータは、埋め込み表現によって数値型(ベクトル値)のデータに変換した後に、ニューラルネットワークに入力されることになります。
この際、「異なる種類のデータが同一の埋め込み表現を共有する」ということがあり得ます。たとえば、「過去にレコメンドされた動画」と「これまでに視聴した動画」は、生のデータ形式としては、どちらも「動画ID」の集まりとなります。そこで、「動画ID」を高次元のベクトルに変換する埋め込み表現を1つ用意して、どちらも同じ埋め込み表現でベクトルに変換します。これを模式的に表したものが、図1になります。
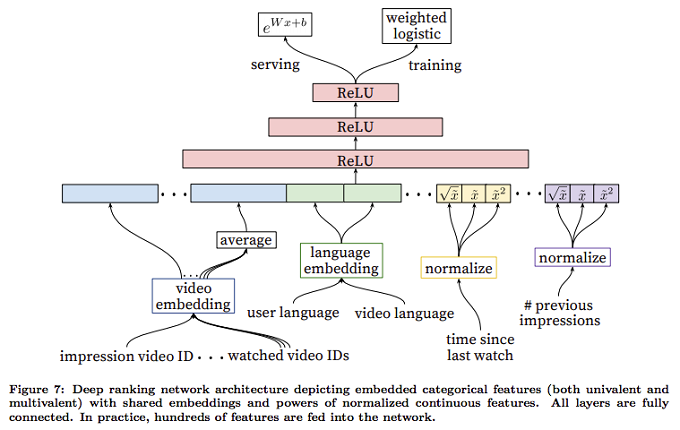
図1 「ランキングモデル」のアーキテクチャー(論文より抜粋)
図1の左下を見ると、「Impression video ID(過去にレコメンドされた動画)」と「watched video ID(これまでに視聴した動画)」が共通の「video embedding(埋め込み表現)」を用いていることがわかります。論文の中では、埋め込み表現を共有することで、汎化性能が上がり、さらに、学習時間の短縮、あるいは、必要なメモリー容量の削減と言ったメリットが得られたことが説明されています。また、「これまでに視聴した動画」のように複数の動画IDを含むデータは、それぞれをベクトルに変化した後に、データ全体の平均を取ります。この点は、前回説明した候補選択モデルと同じです。
ちなみに、「過去にレコメンドされた動画」を特徴量として用いる理由はなんでしょうか? これは、続けてレコメンドを表示する際に、毎回、新たな動画をレコメンド対象に含めるために必要となります。この特徴量を用いることで、これまでに何度かレコメンドされているにもかかわらず、一度も視聴されていない動画がレコメンド対象から外れるといった効果が期待できます。この他には、これまでに視聴した動画のチャネル、あるいは動画のカテゴリーといった情報も重要な特徴量となります。
一方、図1の「time since last watch(該当の動画を最後に見た時からの経過時間)」、あるいは、「# previous impressions(該当の動画がレコメンドされた回数)」は、数値型データの例になります。数値型データについては、0.0 〜 1.0の範囲の浮動小数値に変換する正規化(normalize)の処理を行った後に、その値に加えて、平方根、および、2乗を計算したものをそれぞれニューラルネットワークに入力します。これは数値型データに対する「特徴量エンジニアリング」として、標準的に用いられるテクニックの1つです。
最後に、このモデルを学習する際は、各動画の「視聴時間」を正解ラベルとします。第48回で説明したように、単純に動画のリンクをクリックするだけではなく、その後、きちんと動画を見続けるかどうかを考慮してレコメンデーションを行うことになります。実際の学習処理では、前回の「候補選択モデル」と同様に、正解データと同時に「不正解データ」、すなわち、まだ見たことがない動画のデータを組み合わせます。この際、不正解データについては、共通の負の値を視聴時間として設定して学習を行います。レコメンドを行う際は、レコメンド候補の動画すべてについて、その視聴時間を予測します。最終的には、この予測視聴時間のランキングにより、レコメンドされる動画が決まります。
今回は、2016年に公開された論文「Deep Neural Networks for YouTube Recommendations」をもとにして、YouTubeのレコメンデーションシステム、特に「ランキングモデル」の部分を説明しました。論文の中では、モデルを構成するニューラルネットワークのサイズによる予測精度の違いなども紹介されていますので、興味のある方は、ぜひ論文の方も参照してください。
今回は、記念すべき第50回の記事となりました。そして、いよいよクリスマスシーズンということで、12月は連載のお休みをいただきます。次回の記事は、2019年の1月にお届けしたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































