これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に引き続き、2018年に公開された論文「Population Based Training as a Service」、および、それに関連する2017年の論文「Population Based Training of Neural Networks」を紹介します。今回は、2つ目の論文で提案された、新しいハイパーパラメーターチューニングの手法である「Population Based Training」の基本的な手続きを説明します。
新しい手法を説明する前に、まずは、既存の手法の課題を整理しておきます。まず1つは、前回も触れたように、チューニングに長い時間を要するという問題です。ハイパーパラメーターに値を設定して学習処理を実施した後に、その評価結果を見て、次に試すべき値を推定するという作業を繰り返すので、学習処理を何度も繰り返す必要があります。
もう1つの課題は、学習処理中のハイパーパラメーターの動的な変更です。たとえば、学習率の値は、学習処理の進行にあわせて変化させることで、パラメーター(モデルに含まれるウェイトの値)が効率的に最適化できることが知られています。同じことは、学習率以外のハイパーパラメーターにもあてはまります。しかしながら、学習中の変化まで含めると、ハイパーパラメーターの値の組み合わせは膨大なものとなり、学習を繰り返しながら最適値を探していくという手法そのものが困難になります。
「Population Based Training」は、これらの課題に対応できる手法となります。ただし、あらゆる種類のハイパーパラメーターに対応できるわけではありません。ニューラルネットワークのレイヤー数など、モデルの構造を変化させるもの、より正確に言うと、モデルに含まれるウェイトの構成を変化させるハイパーパラメーターには適用できません。その理由については、この後で説明する、具体的な手続きを見れば理解できるものと思います。
Population Based Training(以下、PBT)では、ハイパーパラメーターに異なる値を設定した学習処理を並列に実行します。また、それぞれの学習処理を「エージェント」と呼びます。この時、従来のハイパーパラメーターチューニングと異なるのは、エージェントによる学習処理を最後まで実施しないことです。一定の時間だけ学習を進めたら、その時点のウェイトを用いて、それぞれのモデルの性能を評価します(ここでは、これを中間評価点と呼びます)。そして、性能が悪いエージェントは、その時点で学習を打ち切り、他の性能がよいエージェントのウェイトの値をコピーして、そこから学習を再開します。それぞれのエージェントは、ハイパーパラメーターの値が異なるので、同じウェイトから出発しても、それぞれの学習の進み方(ウェイトの変化)は異なる点に注意してください。その後、一定の時間が経過したら、再度、その時点で性能が悪いエージェントに対して、性能がよいエージェントのウェイトをコピーするということを行います。
説明用の簡単なモデルで、この手続きの様子を表したものが図1になります。
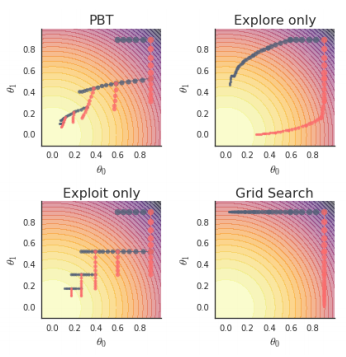
図1 Population Based Trainingの説明用モデル(論文より抜粋)
はじめに、右下の「Grid Search」を見てください。これは、ウェイトの値を2つ持ったモデルで、右上の値から出発して、左下の最適値に到達することが目標となります。ただし、この例では、説明のために、あえて不適切なハイパーパラメーターを設定しており、青色のエージェントは左方向へ、赤色のエージェントは下方向へと進んでしまいます。つまり、どちらのエージェントも最適値に達することができません。
一方、これらのエージェントに対して、さきほどのPBTの手順を適用したものが、左下の「Exploit Only」になります。右端の中央付近で枝分かれが生じていますが、ここが、最初の中間評価点になります。この場合、赤色のエージェントの方が性能がよかったため、青色のエージェントは、強制的に赤色のエージェントと同じ場所(同じウェイトの値)に移動させられます。この後、学習を再開すると、赤色のエージェントはさらに下に進み、一方、青色のエージェントは、その点から左に向かって進みます。この後、次は、青色のエージェントが枝分かれしていますが、ここが2回目の中間評価点です。今回は、青色のエージェントの方が性能がよかったため、赤色のエージェントは、強制的にこの位置に移動させられます。これを繰り返すことにより、全体として、真の最適値(図の左下)に近づいていくことがわかります。
これはまた、学習中にハイパーパラメーターの値を変更していることにもなります。つまり、赤色のエージェントと青色のエージェント、それぞれのハイパーパラメーターの値を交互に入れ替えることで、最適値にいたる経路を実現しています。学習中のハイパーパラメーターをどのように変更していくかを事前に決定するのは、簡単なことではありません。PBTでは、複数のエージェントを利用することで、ハイパーパラメーターの動的な変更を巧妙に実現していることになります。
また、ここまでの説明は、本来のPBTを単純化した手続きになっています。本来のPBTでは、中間評価点において、それぞれのエージェントについて、ハイパーパラメーターにランダムなゆらぎを与えます。図1の左上にある「PBT」がその例になっており、それぞれのエージェントの移動方向が中間評価点ごとに少しづつ変化していることがわかります。これにより、エージェント数よりもさらに多くの種類のハイパーパラメーターの値を探索することができるのです。
今回は、2017年に公開された論文「Population Based Training of Neural Networks」に基づいて、Population Based Trainingの基本的な手続きを説明しました。現実の機械学習モデルに適用する際は、モデルの特性にあわせて、この手続きをさまざまにアレンジすることになります。次回は、そのような実例について解説を進めたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































