これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に引き続き、2018年に公開された論文「Population Based Training as a Service」、および、それに関連する2017年の論文「Population Based Training of Neural Networks」を紹介します。前回は、2つ目の論文で提案された、新しいハイパーパラメーターチューニングの手法である「Population Based Training(PBT)」の手続きを説明しましたが、今回は、同じ論文で紹介されれている、PBTの実際の適用例を紹介します。
上述の論文では、強化学習(ビデオゲームの自動プレイ)、機械翻訳、GAN(画像生成)の3種類のタスクについて、PBTを適用した結果が示されています。図1は、それらの結果をまとめたものですが、いずれも、過去の記録を上回る成果が得られています。ここに示された過去の記録は、DeepMindの研究チームによる記録であることを考えると、PBTが現実的に有効な手法であることが感じられるのではないでしょうか。
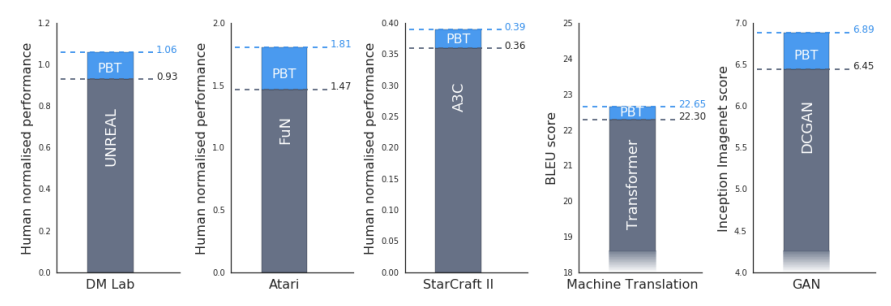
図1 さまざまな機械学習のタスクにPBTを適用した結果(論文より抜粋)
今回は、特に、強化学習の例について、PBTの対象となったハイパーパラメーターの種類や中間評価点におけるエージェントの入れ替え方法などを紹介します。
強化学習への適用例としては、UNREAL、Feudal Networks、A3Cと呼ばれる既存のアルゴリズムに対して、PBTを適用した結果が紹介されています。たとえば、UNREALでは、Labyrinthと呼ばれる3Dの迷路ゲームを自動でプレイするエージェントの学習を行います。この際、エージェントは、実際にゲームをプレイしながら、行動のパターンとそれに伴う報酬(ゲームの得点)のデータを集めていき、これを用いて学習処理を行います。この学習処理におけるハイパーパラメーターには、学習率、エントロピーコスト(エージェントが極端な動作をしないための正則化の強さ)、RNNの展開数(何ステップ分の動作を予測するか)があり、これらにPBTを適用しています。
そして、PBTを適用する際は、学習処理を並列に行うエージェント数、中間評価点を設定するタイミング、性能のよいエージェントのウェイトをコピーする方法などを決める必要があります。論文で紹介されている例では、エージェント数は10〜80で、中間評価点は勾配降下法による学習を100万〜1,000万回実施したタイミングとなっています。また、ウェイトをコピーする方法には、2種類の例があります。1つは、それぞれのエージェントに対して、比較対象のエージェントをランダムに選択して、もしも、比較対象のエージェントの方が優れていれば、そのウェイトをコピーしてくるという、ランダムサンプリングの方法です。もう1つは、すべてのエージェントの性能をランク付けして、下位20%のエージェントのそれぞれに対して、上位20%のエージェントを1つランダムに選択して、そのウェイトをコピーするという方法です。いずれの場合も、ランダムな要素を加えることで、局所的な最適解に陥らない工夫がなされています。
そのほかには、ウェイトをコピーしたタイミングでハイパーパラメーターにランダムなゆらぎを与えるというテクニックもありました。この論文では、1%程度のランダムなゆらぎを与える方法のほかに、事前に定義した確率分布からサンプリングして再設定するという方法が紹介されています。
次の図2は、UNREALのアルゴリズムについて、PBTを適用した場合とそうでない場合について、性能がどのように向上していくかを示したグラフになります。
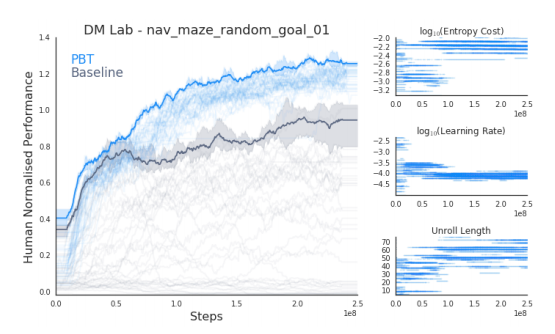
図2 学習ステップごとの性能向上の様子(論文より抜粋)
PBTを適用しない場合(黒色のグラフ)は、比較的に早い段階で性能の向上が頭打ちになっていますが、PBTを適用した場合(青色のグラフ)は、それ以降も性能の向上が続いていることがわかります。ハイパーパラメーターを動的に変化させることにより、局所的な最適解に陥らずに、より適切な領域でのウェイトの探索が行われていることが想像できます。これを実際にビジュアライズすると、図3のようになります。

図3 PBTにおけるハイパーパラメーターの変化の様子(論文より抜粋)
これは、Feudal Networksと呼ばれるアルゴリズムにPBTを適用した際に、各エージェントのハイパーパラメーターがどのように変化したかを表現したものです。ピンク色の点が初期値になりますが、大部分のエージェントは、途中で線が途切れていることがわかります。これは、この点において、他の(より優れた)エージェントのウェイトがコピーされたことによるものです。そして、より優れたエージェントは、自身のコピーを持つことによって、どんどん枝分かれして、特定の領域を集中的に探索している様子が見て取れます。
今回は、2017年に公開された論文「Population Based Training of Neural Networks」に基づいて、Population Based Trainingの適用例を紹介しました。次回は、その他の例を続けて紹介すると共に、2018年に公開された論文「Population Based Training as a Service」で提案されている、PBTのクラウドサービス化について説明したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































