これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に引き続き、2018年に公開された論文「Population Based Training as a Service」、および、それに関連する2017年の論文「Population Based Training of Neural Networks」を紹介します。今回は、PBTの適用例に加えて、PBTのクラウドサービス化について説明します。
前回は、2つ目の論文「Population Based Training of Neural Networks」から、強化学習に対するPBTの適用例を紹介しました。今回は、同じ論文から、GAN(画像生成)に対する適用例を紹介します。GAN(Generative Adversarial Networks)は、画像生成に用いられるディープラーニングの手法で、画像を生成するGeneratorモデルと、トレーニング用画像とその他の画像を識別するDiscriminatorモデルを同時に学習するという特徴があります。Generatorは、「Discriminatorがトレーニング用画像と(誤って)判定する画像を生成する」ことをゴールとして、Discriminatorは、「Generatorが生成した画像をその他の画像であると正しく判定する」ことをゴールにします。これにより、Generatorは、トレーニング用画像に非常に近い画像が生成できるようになります。
しかしながら、GANの学習プロセスは不安定で、特定の画像しか生成しなくなる、あるいは、いつまでも生成画像が一定範囲のパターンに収束しないといった現象がしばしば発生します。特に、2つのモデルを同時に学習させることから、ハイパーパラメーターをチューニングする際は、それぞれのモデルのハイパーパラメーターを関連付けて考える必要があり、ベストな組み合わせを見つけ出すのは相当に困難です(ほとんどの場合、両方のモデルには共通の値がセットされていました)。そこで、PBTによって、2つのモデルのハイパーパラメーターを個別に最適化しようというのが、ここでのアイデアになります。
具体的には、それぞれのモデルの学習率を最適化の対象としてPBTを適用しており、前回の図1にあるように、従来の性能を上回る結果が得られています。次の図1は、学習の進行に伴うハイパーパラメーター(学習率)の変化を表すグラフになります。
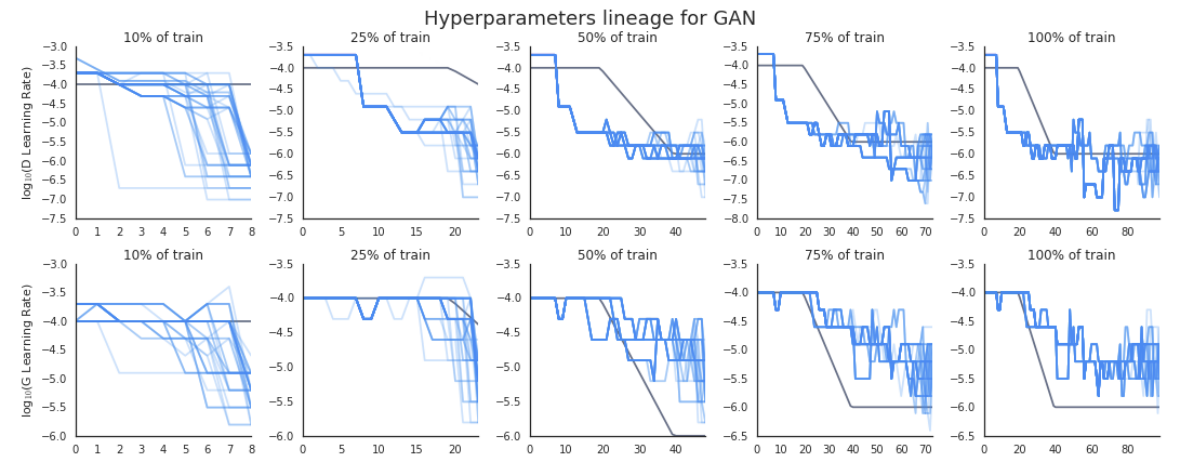
図1 PBTによる学習率の変化(論文より抜粋)
たとえば、一番左の列は、学習が10%まで進んだ時点において、各エージェントがたどった学習率の変化を表します。途中で他のエージェントの値がコピーされた場合、上書きされた古い方の値は、グラフには含まれていません。上の列は、Discriminatorに対する学習率で、下の列は、Generatorに対する学習率です。さらに、それぞれのグラフには、これまで経験的に用いられてきた学習率が黒線で示されています。一番右にある、学習が最後まで進んだ状態でのグラフを見ると、Discriminatorについては、経験値よりもやや小さめ、Generatorについては、経験値よりもやや大きめの値になっています。それぞれのモデルのハイパーパラメーターを個別に設定するというアイデアが、確かにうまく働いているようです。
PBTに関する最後の話題は、クラウドサービス化のアイデアになります。第54回に説明したPBTの手続きを思い出すと、指定のハイパーパラメーターで一定の期間だけ学習を続けるエージェント群と、その結果を用いて、次のステップ(どのエージェントの結果をどのエージェントにコピーするか)を決定する「コントローラー」の2つの仕組みが組み合わされていることがわかります。そこで、この2つをAPIで結合するというアイデアが、冒頭の1つ目の論文「Population Based Training as a Service」で紹介されています。具体的には、図2のようなアーキテクチャーになります。
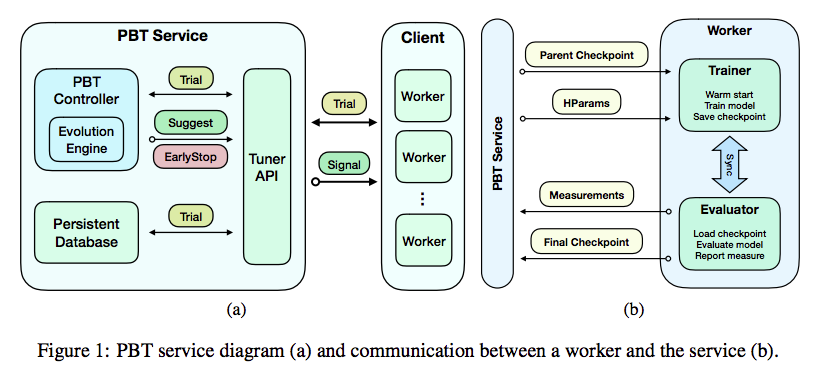
図2 PBTサービスのアーキテクチャー
ここには、(a)と(b)の2つの図がありますが、それぞれの右側にある「Worker」が、指定のパラメーター値で学習を行うエージェント群に相当します。そして、左側にある「PBT Service」がコントローラーの役割を果たします。この部分に、PBTの中核となるアルゴリズムを実装しておき、Worker、すなわち、多数のエージェントをバックエンドとしてAPI経由で利用します。それぞれのエージェントは、並列に学習処理を進めることができるので、このバックエンド部分には、クラウドを用いた並列分散処理が有効活用できる形になっています。
今回は、Population Based Trainingの適用例、そして、それをクラウドサービス化するアーキテクチャーのアイデアを紹介しました。図2のバックエンド部分(Worker)には、既存の機械学習サービス(Cloud ML Engine)を利用することもできるでしょう。興味のある方は、コントローラー部分を独自に実装してみてはいかがでしょうか?
次回は、エンジニア組織における、技術情報の共有方法に関する話題をお届けしたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































