
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2019年に公開された論文「Cache-aware load balancing of data center applications」を元にして、サーチエンジンのロードバランシングに関するアルゴリズムを紹介します。検索対象の単語ごとに担当するサーバーを分けて、サーバー内部のキャッシュのヒット率を高めるというシンプルなアイデアですが、複数の単語を含む検索文に適用するには、すこしばかり数学的な考え方が必要になります。今回は、具体的なアルゴリズムを説明する準備として、システム全体のアーキテクチャーを整理しておきます。
ロードバランサーを用いた負荷分散には、いくつかの基本パターンがあります。すべてのサーバーに均等にリクエストを割り当てるラウンドロビンのほか、サーバーの負荷に応じて、リクエストの割り当てを増減するという方法もあります。さらに、より高度な方式としては、リクエストの内容に応じて、割り当て先のサーバーを変更するという方法(コンテンツベースのロードバランシング)もあります。リクエストの内容によって、それを処理できるサーバーが分かれている場合は、コンテンツベースのロードバランシングが必須となります。
Googleのサーチエンジンでは、検索のメイン処理(検索文に対して検索結果のリストを返却する処理)は、すべてのサーバーが同等の機能を提供するように設計されており、コンテンツベースのロードバランシングは必須ではありません。しかしながら、メモリキャッシュのヒット率を考えると、検索対象の単語ごとにサーバーを分けることで、検索の処理効率が向上することがわかります。これは、次のような検索処理の仕組みに由来します。
まず、サーチエンジンの裏側には、検索対象の単語ごとに、検索結果の候補となるWebサイトのID番号をまとめたデータベースがあり、その内容はフラッシュメモリーに保存されています。(論文中では、「データベース」という言葉は使われていませんが、ここでは、説明をわかりやすくするためにデータベースと呼んでいます。)単語ごとにまとめた、ID番号の集合をPostings List(PL)と言います。複数の単語からなる検索文を受け取ったサーバーは、そこに含まれる単語ごとに、対応するPLをデータベースから取得して、サーバー上のメモリキャッシュに保存します。その後、これらのPLに含まれるWebサイトについてランク付けの処理を行って、その結果を返却します。この際、データベースからPLを取得する部分が、最も処理に時間のかかるボトルネックとなります。そのため、特定のサーバーが同じ単語を連続して処理するようにすれば、メモリキャッシュに保存された前回の検索結果を利用する事で、データベースへのアクセスを省略して、全体の処理速度を向上することができます。
ここで問題になるのは、1つの検索文には複数の単語が含まれるという点です。仮に、1つの検索文には、1つの単語しか含まれないとすれば、検索処理を割り当てるべきサーバーは一意に決まります。しかしながら、複数の単語を含む場合は、図1のような状況が発生します。
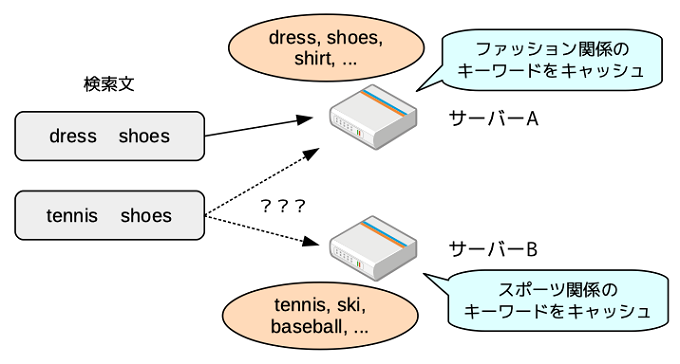
図1 検索文に対して処理を割り当てるサーバーを決定する様子
この例では、ファッションに関連する単語を担当するサーバーAと、スポーツに関連する単語を担当するサーバーBがあるという想定です。仮に、検索文が「dress shoes」であれば、どちらの単語もサーバーAが担当しているので、処理を割り当てるサーバーは、Aに決まります。一方、検索文が「tennis shoes」の場合、「tennis」と「shoes」で担当するサーバーが異なるので、どちらのサーバーに処理を割り当てるべきかは自明ではありません。いずれを選択しても、何らかのキャッシュミスが発生して、データベースへのアクセスが発生する可能性が高くなります。しかしながら、このような場合でも、検索システム全体の効率性を考えて、どちらに割りてる方がよりよいかを決定するアルゴリズムを考えることはできるはずです。
冒頭の論文では、実際にこれを決定する「term-affinitized replica selection(TARS)」と呼ばれるアルゴリズム、そして、過去の検索ログデータを用いて、サーバーごとに担当する単語を効率的に割り当てる方法が説明されています。図2は、実際の構成を単純化して図示したものになります。
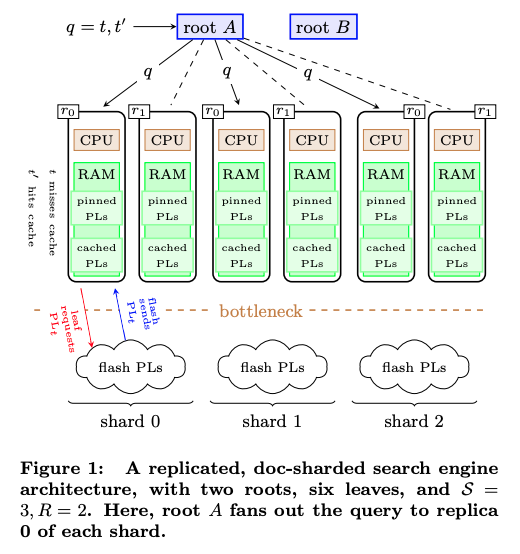
図2 単語のグループ分けによる負荷分散の仕組み(論文より抜粋)
図の下にあるシャード(shard 0〜shard 2)は、単語のグループ分けに当たります。この例ではすべての単語を3つのグループに分けて、それぞれに担当するサーバーを割り当てます。ただし、1つのグループを1台のサーバーだけで担当するのは現実的ではありませんので、グループごとに複数のサーバーで、さらなる負荷分散を行います。この例では、それぞれのグループに対して、2台のサーバー(レプリカ:r0、r1)が用意されており、全体として、6台のサーバーで負荷分散しています。図の上にある「root」は、ロードバランサーのフロントエンドに当たるサーバーで、受け取った検索文に対して、前述のTARSアルゴリズムで振り分け先のシャードを決定した後に、さらに該当のシャードを担当する複数のサーバーに対して、通常のロードバランシング処理を行います。また、図中の「pinned PLs」というのは、特に検索頻度の高い項目で、これは、すべてのサーバーに共通で、事前にメモリ上に読み込んであります。
この仕組みは、2015年より、Googleのサーチエンジンシステムで実際に使用されており、以前に比べて、キャッシュミスの割合をおよそ半分に減らすことができたそうです。
今回は、2019年に公開された論文「Cache-aware load balancing of data center applications」を元にして、サーチエンジンのロードバランシングの仕組みを紹介しました。次回は、この仕組みの主要要素となるTARSのアルゴリズム、そして、単語のグループ分け(シャーディング)を決定する方法について、解説を進めたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































