
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に引き続き、2019年に公開された論文「Cache-aware load balancing of data center applications」を元にして、サーチエンジンのロードバランシングに関するアルゴリズムを紹介します。今回は、検索文に含まれる単語から、処理を割り当てるサーバーを選択する「TARS」と呼ばれるアルゴリズム、そして、TARSによる振り分けの結果、システム全体のキャッシュのヒット率が最大になるように、サーバー群をグループ分けする方法を説明します。
まず、ロードバランシングの前提となる考え方として、前回の図1を再確認しておいてください。いま、サーバーA、B、C・・・は、それぞれに優先して担当する単語のグループが決まっているとします。そして、サーバーAがある単語tについてのPL(検索結果の候補となるWebサイトのID番号の集合)を取得する際に、データベースから読み込む必要があるデータ量(正確に言うと、メモリページ数)をw(A,t)とします。これは、該当データがキャッシュにあれば0で、キャッシュになければ、単語tに対するPLのメモリページ数に一致します。サーバーB、C・・・についても同様に、w(B,t)、w(C,t)・・・とします。ここでは、これらの値を「ウェイト」と呼びます。ウェイトの値をどう見積もるかは別にして、ここでは、まずは、これらの値は分かっているものとします。
この場合、複数の単語t1、t2・・・を含む検索文について、これをサーバーAに割り当てた場合、データベースから読み込むデータの総量は、w(A,t1)+w(A,t2)+・・・という足し算で計算できます。実は、TARS(term-affinitized replica selection)のアルゴリズムはとてもシンプルで、この計算で決まるデータ量が一番小さくなるサーバーを選択するというものになります。
――― という説明をすると、これ以上考えることはなさそうにも思われますが、そんなことはありません。前回の図1にあるように、1台のサーバーは複数の単語を担当するので、単語のグループ分けの方法により、システム全体としての効率(キャッシュのヒット率)は変化することになります。これは、一種の組合せ最適化問題で、このチューニングが最も難しい部分になります。
また、通常のロードバランサーと同様に、それぞれのサーバーの負荷も考慮に入れる必要があります。実際には、さきほど説明したデータの総量と、その時点でのサーバーの負荷の組み合わせによって、最終的な振り分け先が決定されます。
さきほど、単語のグループ分けにより、システム全体としての効率が変わるといいましたが、これは、実際にユーザーから送られてくる検索文の傾向に依存します。冒頭の論文では、一定のアルゴリズムに基づいて、過去の検索文のログデータから最適なグループ分けを決定するという方法を提案しています。
まず、図1は、このようなグループ分けの模式図になります。ここでは、V0とV1の2種類のグループが描かれています。左側に並んでいるのは、個々の単語で、この例では、「dress」と「shoes」は同じグループになっています。そして、右側に並んでいるのは、ログデータに含まれるすべての検索文です。「tennis shoes」や「dress shoes」と言った検索文があったという想定です。これらは、前述のTARSのアルゴリズムで決まるグループの中に描かれています。つまり、「tennis shoes」と「dress shoes」は、どちらも、グループV1のサーバーに割り当てた場合に、データベースから読み込むデータ量が最も少なくなるということです。
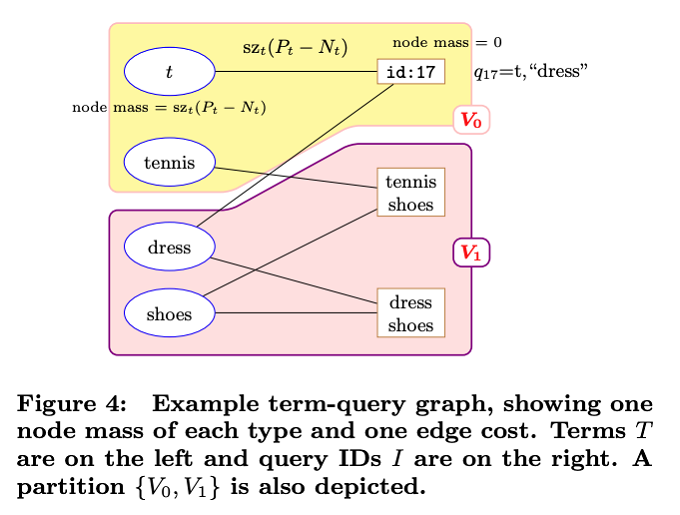
図1 単語のグループ分けの模式図(論文より抜粋)
ただし、ウェイトの値が具体的に分からなければ、実際に割り当てるグループを決定することはできません。そこで、まずは、簡単のために、それぞれのウェイトについて、
・自身が担当する単語の場合は0(つまり、PLはかならずキャッシュに乗っている)
・自身が担当しない単語の場合は、PLのサイズに比例する(つまり、PLがキャッシュに乗っていない確率は一定)
という単純な仮定を置きます。この仮定に基づくと、図1の場合、検索文「dress shoes」は、グループV1に割り当てることで、ウェイトの値は0になります。一方、検索文「tennis shoes」の場合、グループV1に割り当てた場合、単語「tennis」に対するウェイトの値が発生します。あるいは、グループV2に割り当てた場合は、単語「shoes」に対するウェイトの値が発生します。今の場合、「tennis」と「shoes」のそれぞれのPLのサイズを比べると、「shoes」の方が大きい(つまり、検索結果の候補となるWebサイトは、「shoes」の方が多くある)ために、TARSのアルゴリズムにより、V1に割り当てられているということになります。
このようにして、単語のグループ分けを一つ決めると、前述の仮定と、各単語に対応するPLの実際のサイズを元して、すべての検索文に対して、割り当てるべきグループが一意に決まります。また、この状態で、これらすべての検索文を処理した場合に、データベースから取得されるデータの総量も計算することができます。(本来は、検索処理が進むにつれて、各サーバーのキャッシュの状態が変化するため、前述の単純な仮定は成り立たなくなりますが、いまはその点には目をつぶります。)そして最後に、「単語のグループ分けのあらゆるパターン」について、この手順にしたがってデータベースから取得されるデータの総量を計算すれば、最適なグループ分けのパターンが発見できるというわけです。つまり、取得されるデータの総量が最小になるようなグループ分けを選べばよいのです。
・・・とはいえ、「単語のグループ分けのあらゆるパターン」は、膨大な数になるため、現実的な時間ですべてのパターンを計算することは不可能です(計算機科学の世界では、「NP-hard」と呼ばれる問題にあたります)。そこで、このシステムを開発したチームでは、Googleが開発した、独自の分散グラフ計算システムを用いて、近似的に答えを見つけるという方法を採用しました。さらには、検索処理システムのシミュレーターを作成して、得られたグループ分けに基づいて、実際に発生するキャッシュミスの総量を確認するという検証を行いました。ここまでに説明した手法には、さまざまな仮定が含まれているので、本当にこれが有効なのかと疑問を持つ読者もいたかもしれませんが、シミュレーションの結果によって、実際の効果が確認できるというわけです。
今回は、2019年に公開された論文「Cache-aware load balancing of data center applications」を元にして、サーチエンジンのロードバランシングの仕組みについて、具体的なアルゴリズムと最適化の手法を紹介しました。今回説明した範囲では、簡単のためにいくつかの単純な仮定を置いていますが、論文の中では、これをベースとして、さらに現実のシステムの挙動に近づける手法も説明されています。詳細については、ぜひ、論文を参照してください。また、本文で触れた「独自の分散グラフ計算システム」についても、関連論文が紹介されています。
次回は、シミュレーションによって得られた、さまざまな結果を紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































