
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に引き続き、2019年に公開された論文「Cache-aware load balancing of data center applications」を元にして、サーチエンジンのロードバランシングに関するアルゴリズムを紹介します。今回は、検索処理システムのシミュレーターを用いた評価結果を見ていきます。
これまで説明してきたように、このアルゴリズム(TARS)の目的は、検索処理サーバーが、ある単語についてのPL(検索結果の候補となるWebサイトのID番号の集合)取得する際に、そのデータがメモリー上のキャッシュに保存されている確率を高めて、データベースへのアクセス量を減らすことです。つまり、キャッシュミスの割合をできるだけ低くすることがゴールとなります。
ここで、前回の図1で説明した仕組みを思い出してみましょう。そこでは、サーバーごとに担当する単語を設定しておき、自身が担当する単語についてはキャッシュミスは発生せず、逆に、担当しない単語については、一定の確率でキャッシュミスが発生するという素朴な仮定を置いていました。その上で、過去の検索文に含まれる単語の組み合わせを用いて、キャッシュミスを最小化するようにサーバーごとに割り当てる単語のグループ分けを行いました。それでは、このような方法で、実際のシステムにおけるキャッシュミスは最小化されるのでしょうか? その結果を示したものが図1になります。ここでは、検索サーバーのキャッシュの状況をシミュレーションするプログラムを用いて、実際に発生するキャッシュミスの割合を測定しています。
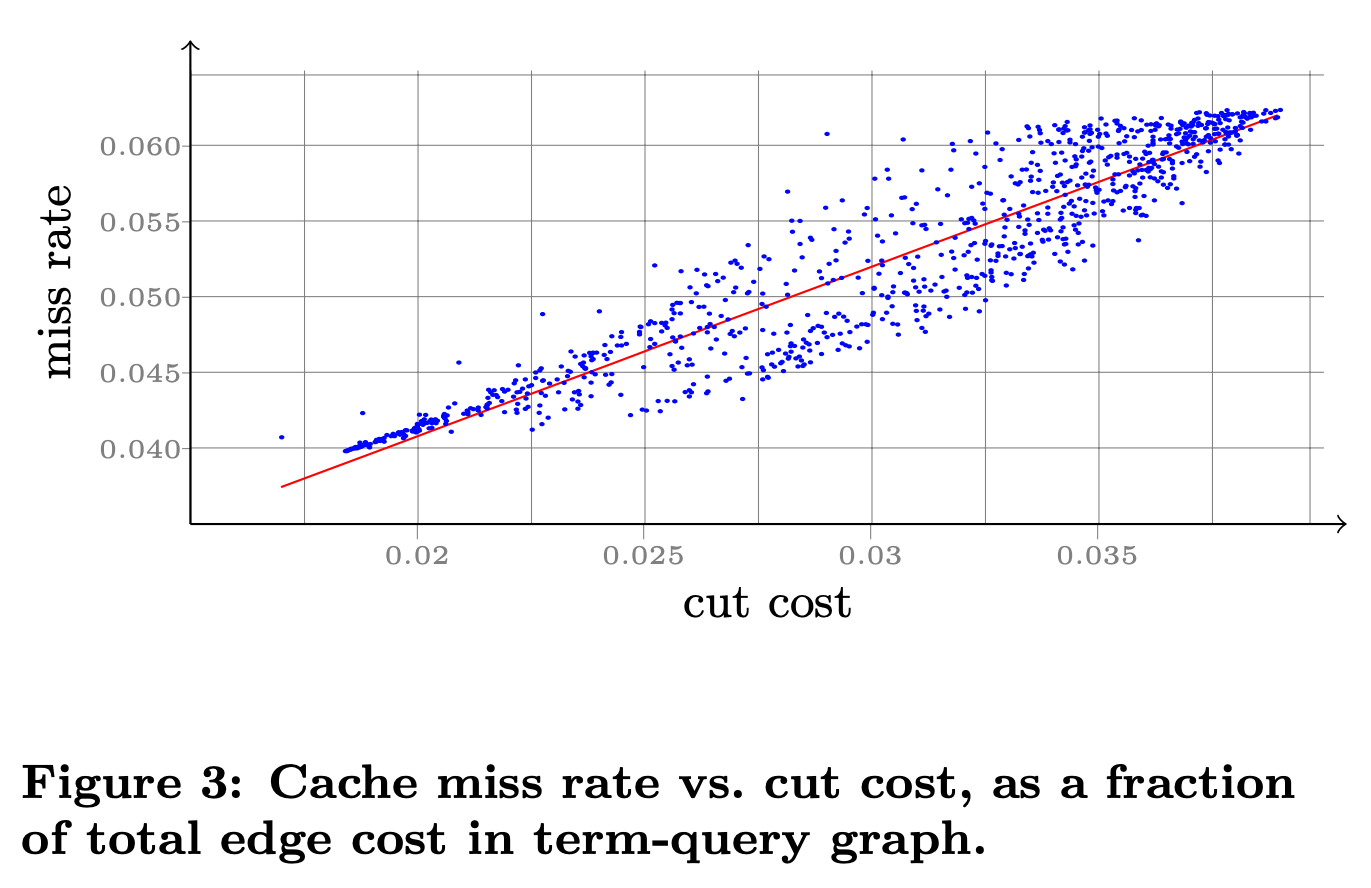
図1 シミュレーションによるキャッシュミスの発生割合(論文より抜粋)
具体的には、単語のグループ分けについて1000種類のパターンを想定して、それぞれについて、「cut cost」(前述の素朴な仮定のもとに計算されるデータベースアクセス量)と「miss rate」(シミュレーションによって得られた実際のキャッシュミスの割合)の関係をプロットしています。これを見ると、cut costが増えると、miss rateも増えると言う直線的な関係があることが分かります。つまり、前述の仮定に基づいて、cut costを小さくするという方針は、キャッシュミスの割合を下げると言う目的に確かに合致しているのです。
また、当然のことながら、サーバーに搭載するキャッシュメモリーの容量によっても、キャッシュミスの割合は変わります。この論文では、同じシミュレーターを用いて、キャッシュサイズによる効果を測定した結果も紹介されています。図2は、ある一定の条件の下に、キャッシュサイズによって、キャッシュミスの割合がどのように変化するかをシミュレーションで測定した結果になります。横軸(キャッシュサイズ)の値は、キャッシュミスが20%になる時のキャッシュサイズを1とした相対値を表します。
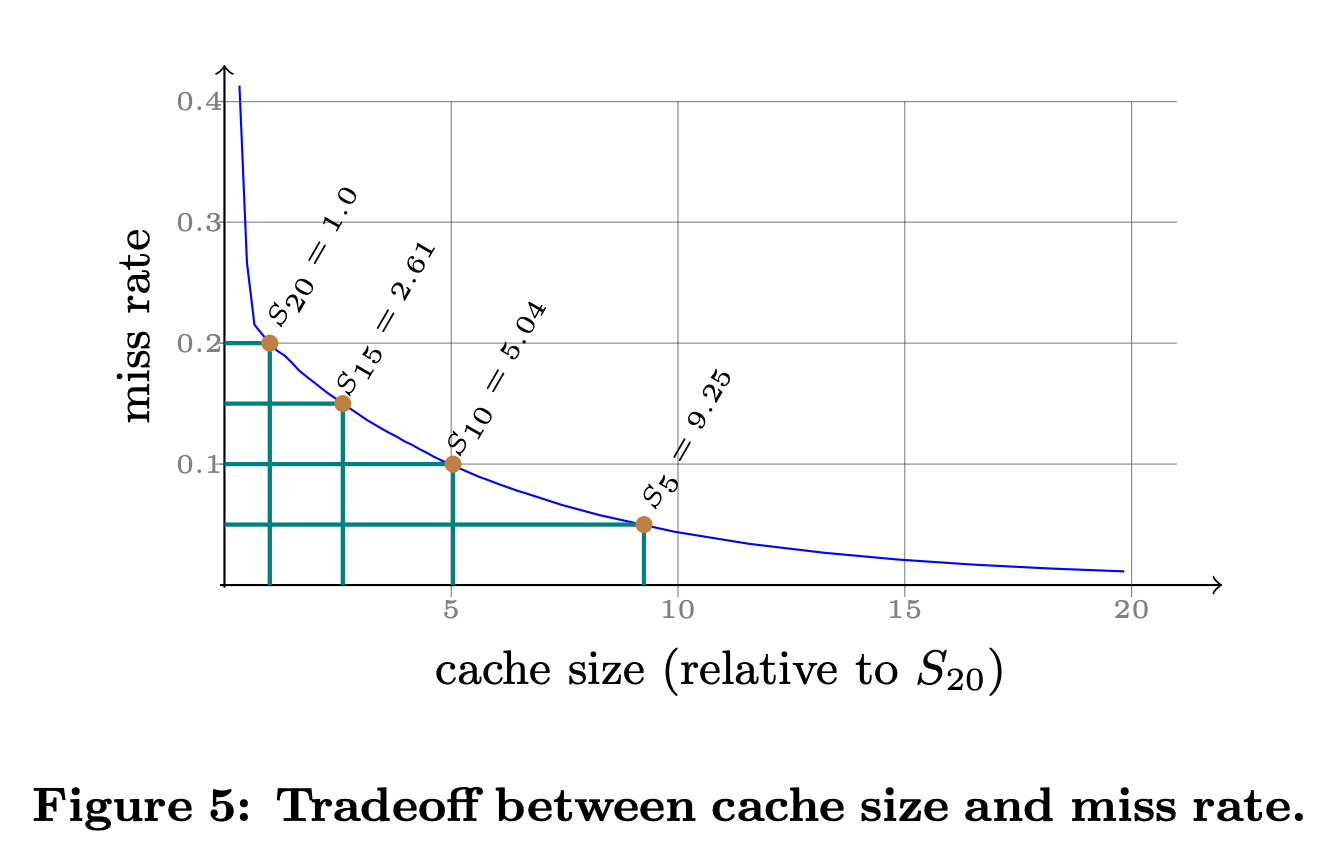
図2 キャッシュサイズとキャッシュミスの関係(論文より抜粋)
この結果を見ると、キャッシュサイズを0から増やしていくと、キャッシュミスの値は、20%までは一気に下がりますが、それ以降の変化は緩やかになることが分かります。この結果を基にして、キャッシュメモリーの搭載に掛かる費用と、そこから得られる効果のバランスを考えることができるというわけです。
先ほども述べたように、このアルゴリズムでは、「あるサーバーが、自身が担当しない単語を処理する場合、キャッシュミスが発生する確率は(すべてのサーバー、単語について)一定である」という素朴な仮定を用いています。しかしながら、前述のシミュレーターを用いれば、実際に発生するキャッシュミスの割合をサーバー、単語ごとに確認することができます。その結果を用いれば、割り当てる単語のグループ分けを改善することができます。具体的には、「素朴な仮定の下にグループ分けを行う」→「シミュレーターでキャッシュミスの確率を計測する」→「計測された確率に基づいて、よりよいグループ分けを発見する」→「シミュレーターでキャッシュミスの確率を計測する」→・・・という処理を繰り返すことで、逐次的に改善を図ります。シミュレーションの結果によると、この処理を20回程度繰り返すと、それ以上は改善が得られないという限界に達したそうです。
そして、図3は、この改善効果をテストした結果になります。ここでは、AS(アジア)、EU(ヨーロッパ)、NA(北米)の複数の地域について、地域ごとの検索ログを用いたシミュレーションを行っています。複数の条件による結果が示されていますが、まず、「FPT」の列は、本論文の成果を適用する前の既存のアルゴリズムによる結果を示します。さらに、「binary/BP」は先ほどの素朴な仮定に基づいたグループ分けを適用した結果、そして、「+IR/BP」の列は、シミュレーターを用いた逐次的な改善処理を適用した結果です。
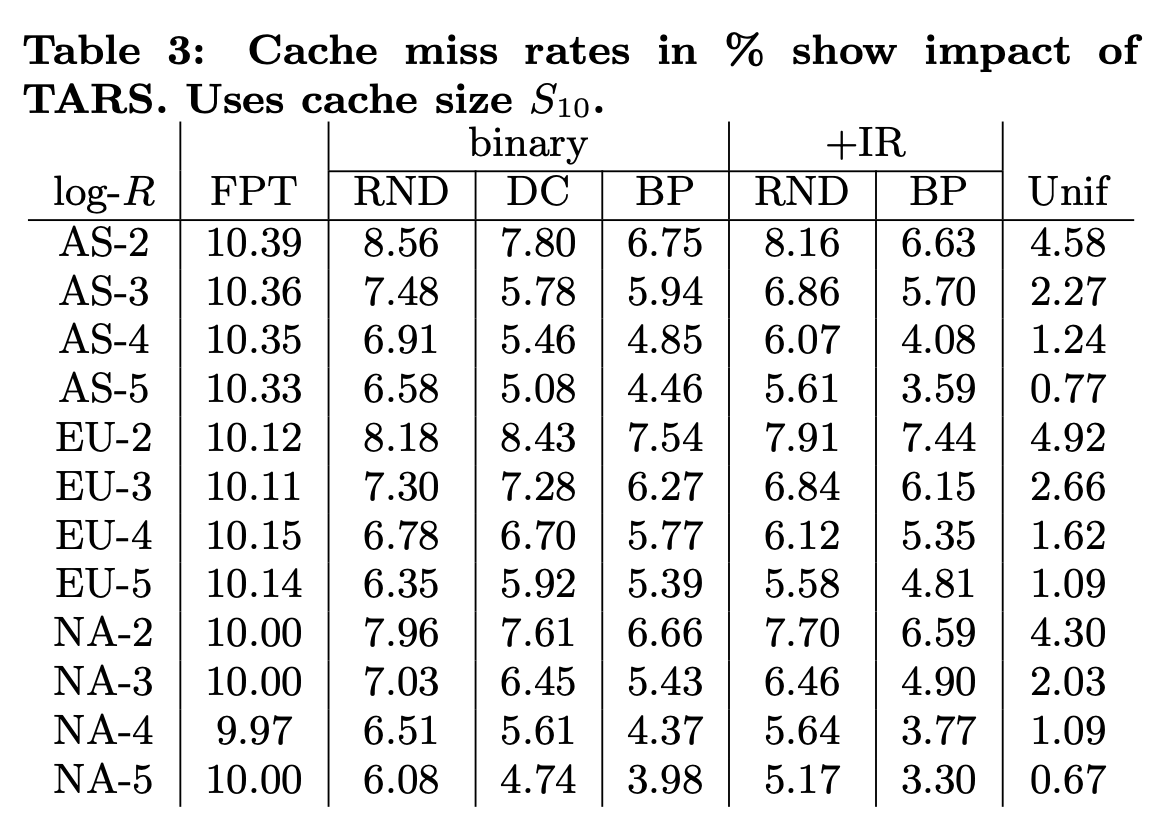
図3 シミュレーションによるテスト結果(論文より抜粋)
ここでは、グループ分けを決定するためのトレーニングデータとは別に、テスト用に取り分けておいたログデータを用いたテスト結果が示されています。地域ごとの変動はありますが、平均的に見て、これまでは10%前後だったキャッシュミスが、5%前後まで低減していることが分かります。
最後に、このアルゴリズム(TARS)を実環境に適用した実験結果を紹介します(図4)。ここでは、3種類の結果が示されていますが、左端が従来の環境、そして、右端が新しいアルゴリズムを適用後の環境に対応します。それぞれの環境に対して、負荷テストツールを用いて、一定量の検索処理を投入した結果が時系列データとして示されています。
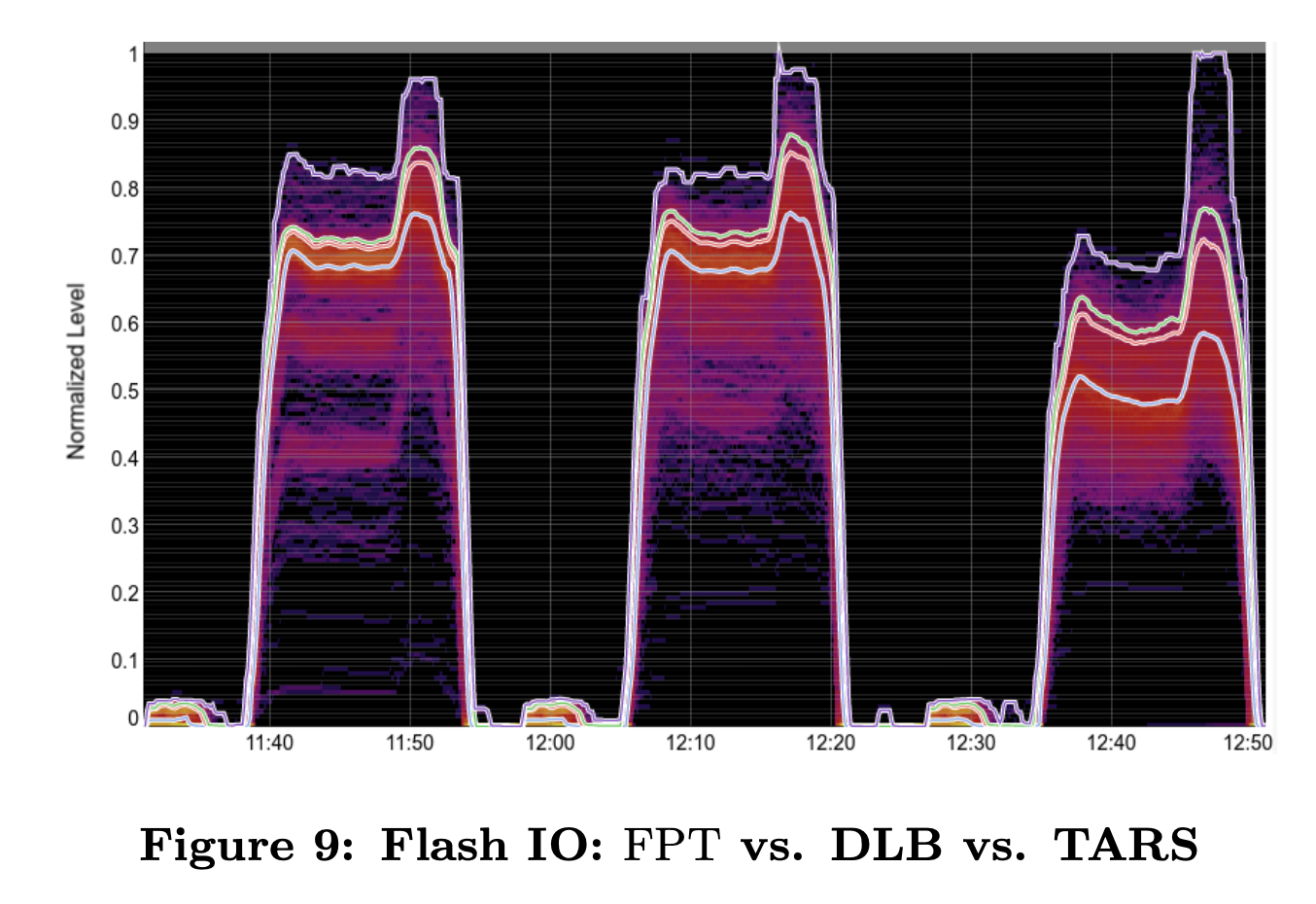
図4 実環境における実験結果(論文より抜粋)
縦軸は、データベースのバックエンドとなるフラッシュメモリーに対するアクセス量で、これが少ないほどよいことになります。複数のカーブは、50、90、95、99.9パーセンタイルに対応しており、たとえば、一番下のカーブは、50%の検索処理に対するアクセス量は、この値以下であると理解することができます。この結果を見ると、フラッシュメモリーに対するアクセス量は明確に低減しており、確かに、サーチエンジンの性能向上に寄与していることが理解できます。
今回は、2019年に公開された論文「Cache-aware load balancing of data center applications」を元にして、サーチエンジンのロードバランシングの仕組みについて、新しいアルゴリズムの性能の測定結果を紹介しました。改善結果を見るためにわざわざシミュレーターを作成するというのは、大袈裟と思う方もいるかも知れませんが、シミュレーションで得られたデータにより、さらにアルゴリズムを改善するという点では、それだけの手間をかける価値はあると言えるでしょう。
次回は、モバイルデバイスを用いた機械学習の話題をお届けしたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































