
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に引き続き、2019年に公開された論文「Data Validation for Machine Learning」を元にして、機械学習モデルの学習データに含まれる異常を検知するシステムを紹介します。このシステムは、機械学習を利用するGoogle社内のプロジェクトで標準的に利用されているもので、その全体像は、前回の図1のようになります。この後の本文は、前回の図1を見ながら読み進めるとよいでしょう。
学習データを収集するシステムである「Training data generation code」が収集・保存した「Training Data」、および、予測対象のデータを収集するシステムである「Serving data generation code」が収集・保存した「Serving Data」は、まずはじめに、「Data Analyzer」によって各種の統計情報が抽出されます。大規模な機械学習システムでは、これらのデータは膨大な量になるため、すべてのデータを個別にチェックするのは困難な場合もあります。あるいは、機械学習システムに特有のデータ異常を検知する上では、生データをそのままチェックするのではなく、事前に前処理を施した方がよい場合もあります。そのために、データの検証に必要十分な情報を抽出するのが、「Data Analyzer」の役割になります。
その後、「Data Validator」は、事前に用意されたスキーマ情報を用いて、データの「型」チェックを行います。次の図1は、学習データとそれに対応するスキーマの例です。スキーマでは、学習データに含まれるそれぞれのフィーチャーについて、データの型(数値データなのか文字列データなのかなど)や、取り得る値の範囲などが指定されており、実際の学習データがその条件にマッチしているかがチェックされます。

図1 学習データとスキーマの例(論文より抜粋)
このスキーマ情報は、データ収集システムが集めるすべてのデータ(フィーチャー)に対して個別に用意する必要があります。さらに、機械学習モデルが前提とするデータ形式を記述する必要があるため、データを提供する側ではなく、機械学習システムをメンテナンスする側、すなわち、機械学習パイプラインのオーナーが作成・管理する必要があります。この時、膨大な学習データに対して手動でスキーマを用意するのは困難ですので、Data Validatorは、Data Analyzerが生成した統計情報を用いて、初期バージョンのスキーマを自動生成します。その後、スキーマに合致しないデータが発見された場合は、パイプライン管理者にアラートをあげて、パイプライン管理者は、これが本当に異常なデータなのか、自動生成したスキーマに問題があったのかを判断します。そして、スキーマに問題があった場合は、ここで適切な修正を行います。
このような観点では、スキーマ情報というのは、機械学習モデル、あるいは、データ収集システムのコードと同じく、メンテナンス作業の対象物と言えます。スキーマの定義ファイルは、ソースコードの一部として、バージョン管理システムで変更履歴を管理していきます。図2は、Google社内のプロジェクトで、スキーマの変更が何回程度発生したかを示すグラフです。大部分のプロジェクトでは、自動生成されたスキーマに対して、手動でアップデートするのは、5回以内に収まっていることがわかります。
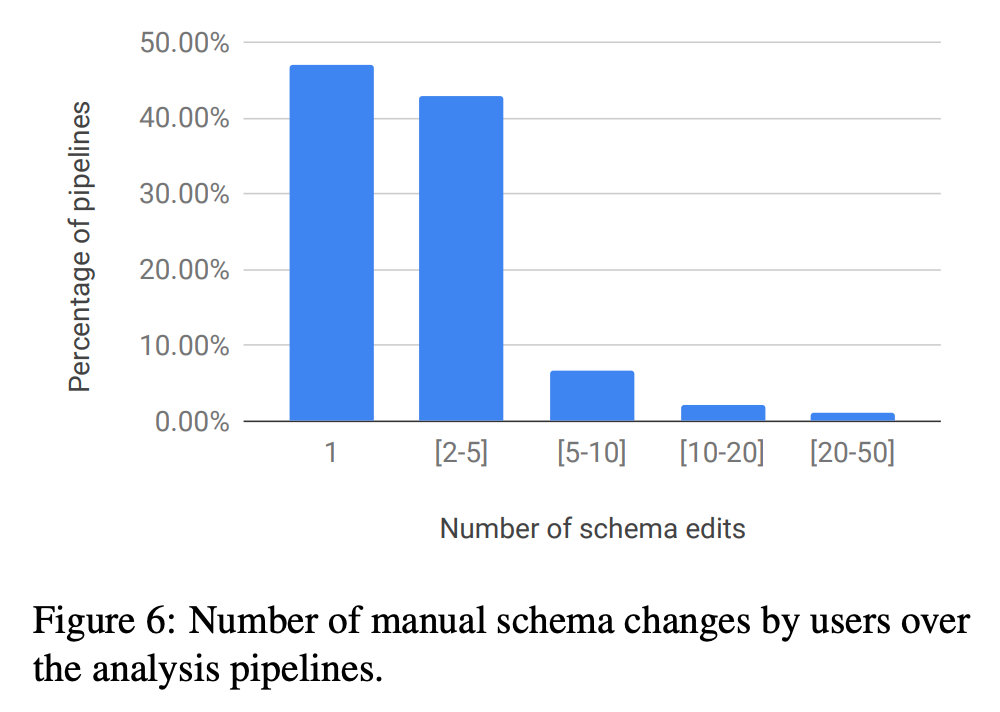
図2 社内プロジェクトにおけるスキーマの変更回数(論文より抜粋)
機械学習パイプラインでしばしば発生する問題の1つに、「Training-Serving Skew」があります。これは、学習用データと予測用データに予期せぬ違いが生まれて、予測精度が下がるという問題です。たとえば、学習データの収集システムにおいて、データの前処理部分に変更を加えて、学習データの構成が変わったにも関わらず、予測用データの収集システムに同じ変更を加えるのを忘れるということがあります。あるいは、データの一部を外部システムからリアルタイムに収集する場合、学習データを収集するタイミングと、予測用データを収集するタイミングで、外部システムの挙動が変わるということもあります。
さらに込み入ったケースとしては、学習に用いられるラベル付きのデータが、特定のデータに偏るといった場合があります。たとえば、動画のレコメンドシステムにおいて、機械学習モデルは、それぞれのユーザーに対して100個の「おすすめ動画」を出力するとします。そして、ユーザーが実際にどれかの動画をクリックすると、「クリックされた」という正解ラベルを付与した新たな学習データが生成されます。しかしながら、機械学習モデルの設計者の意図に反して、この動画配信サービスのアプリケーションは、予測システムから受け取った100個の動画の内、上位の10個だけを表示するように設計されていたのです。この場合、残りの90個の動画が「クリックされた」という正解ラベルを得ることはありません。その結果、上位10個の動画は、再度、おすすめ動画として選択される確率が(モデル設計者の想定以上に)高くなり、その他の動画は、おすすめされる確率がどんどん低くなります。
このような問題を検出するには、学習用データと予測用データを比較して、データの分布に不自然な違いが生まれていないかをチェックする必要があります。Data Validatorは、データの統計値の変化から、このような異常を検知する仕組みも提供しています。
今回は、2019年に公開された論文「Data Validation for Machine Learning」を元にして、機械学習モデルにおける学習データの異常を検知するシステムの紹介を続けました。ここでは、「データスキーマによる異常値検知」と「データ統計値の変化による異常値検知」を説明しましたが、データの統計値をどのように処理するかなどの詳細は、冒頭の論文に記載があるので、興味のある方は参照してください。
次回は、「スキーマから自動生成したデータによるモデルとデータの不整合検知」の仕組み、そして、Google社内おける本システムの適用事例を紹介していきます。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































