
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に引き続き、2019年に公開された論文「Data Validation for Machine Learning」を元にして、機械学習モデルの学習データに含まれる異常を検知するシステムを紹介します。前回は、データスキーマを用いたデータの異常値検知、および、データの統計値に基づく異常値検知の仕組みを説明しました。今回は、スキーマから自動生成したデータを用いて、モデルとデータの不整合を検知する仕組みを紹介します。
ここでは、前々回の図1で、「Model Unit Testing」に当たる部分の機能を説明します。一般に、機械学習モデルを開発する際は、モデルに入力するデータの種類について、一定の想定が置かれます。簡単な例で言うと、ある入力値は負の値をとることはない、と言った想定です。このような前提で設計されたモデルに想定外のデータ(先ほどの例であれば、負の値のデータ)を入力すると、的外れな予想結果が出力されるだけではなく、ソフトウェアエラーが発生して予測システムが停止するななどの問題を引き起こす可能性があります。
前述の想定がデータスキーマに正しく反映されていれば、このような問題を引き起こすデータは、データスキーマによる異常値検知で事前に発見することができます。しかしながら、前回説明したように、初期のデータスキーマは収集したデータから自動生成されるものですので、モデル開発者の意図が正しく反映されているとはかぎりません。あるいは、スキーマをメンテナンスするデータ管理者と、実際にモデルを開発するデータサイエンティストの意思疎通のミスが起きることもあり得ます。
そこで、このような問題を事前に発見するために、スキーマで指定された条件に見合うデータを人工的に生成して、モデルによる予測処理を行うのが「Model Unit Testing」の役割です。一般的なビジネスアプリケーションにおいても、さまざまな入力値をランダムに入力してソフトウェアのテストを行うことがありますが、これと同じ考え方になります。スキーマから自動生成するデータは、あらゆる値の組み合わせを網羅するわけではありませんんが、経験的には、一般的な問題であれば数分程度のテストで発見できると説明されています。Google社内のシステムでは、モデルの開発者がモデルに何らかの変更を加えるごとに、このテストが自動で実行されるようになっているそうです。
冒頭の論文では、Google社内の700種類の機械学習パイプラインに対して、これまでに説明した、TFXの異常値検知システムを適用した結果が示されています。次の図1は、発見された問題の種類ごとに、該当の問題の検知が実装されているパイプラインの割合(Used)と、過去30日間に問題が検知されたパイプラインの割合(Fired)を示しています。たとえば一番上の「New feature column」は、スキーマが定義されていない新しいフィーチャーが(パイプライン管理者が気づかない間に)追加されたという問題を表します。すべてのパイプラインで、この種の問題を検知するように実装されており、10%のパイプラインでこの問題が検知されたということになります。また、最後の「Fixed given Fired」は、2日以内に問題が修正された割合です。
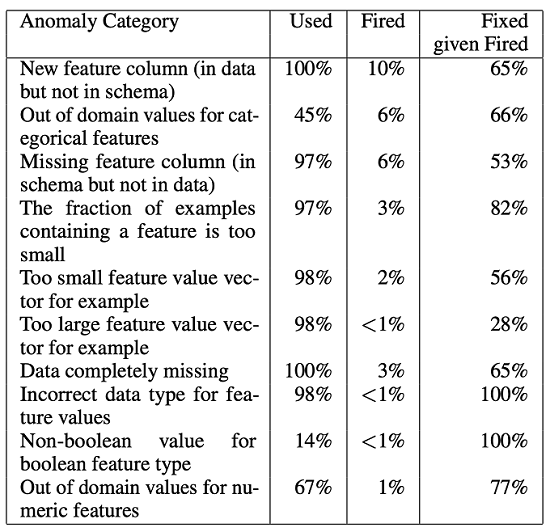
図1 機械学習パイプラインにおける異常データ検知の分析結果(論文より抜粋)
この結果を見ると、すべての問題が解決しているわけではありませんが、これには2つの理由が想定されます。1つは、データ収集システム側の問題で発生した一時的なデータの欠損など、パイプライン側での対応ができない問題だった場合、もう1つは、問題発生のアラートを受け取ったオペレーターが何らかの理由で即座に対応しなかった場合です。後者については、機械学習パイプラインに限らず、人間のオペレーターにアラートをあげるすべてのシステムで起こり得ることです。これに対処するには、単純にアラートを通知するだけではなく、何が問題の原因で、具体的にどのような対応が必要なのかという情報を適切に通知する必要があります。
今回は、2019年に公開された論文「Data Validation for Machine Learning」を元にして、機械学習モデルにおける学習データの異常を検知するシステムの紹介を続けました。論文の中では、今回説明した「Model Unit Testing」の適用結果のほか、Google Playのレコメンデーションシステムなど、具体的な適用システムについての紹介もありますので、興味のある方は、論文の方もぜひ参照してください。
2019年の連載は、今回が最後になります。次回は、年明けの2020年1月に掲載予定ですので、楽しみにお待ちください。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































