
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2017年に公開された論文「Quick Access: Building a Smart Experience for Google Drive」を元にして、Googleドライブの「クイックアクセス」機能を支える機械学習システムについて解説します。今回は、機械学習モデルの構成を中心に説明を進めます。
前回の記事で説明したように、クイックアクセスで用いる機械学習モデルは、過去60日間にユーザーが使用したファイルのそれぞれについて、次にそのファイルを開く確率を予測するというものです。つまり、ユーザーが所有するファイルの属性情報を入力として、0〜1の確率値を出力する予測モデルになります。全体の構成は、図1のようになります。
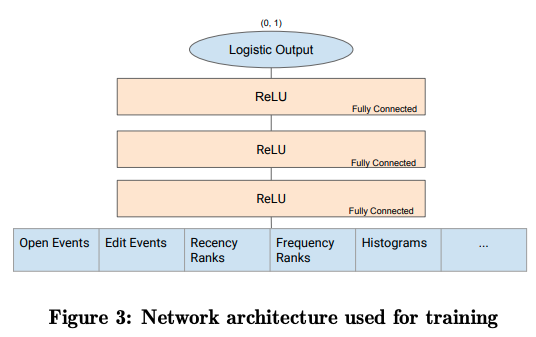
図1 機械学習モデルの構造(論文より抜粋)
これは、複数の全結合層を並べた標準的なフィードフォワードネットワークで、レイヤー数、および、各レイヤーのノード数はハイパーパラメーターチューニング(グリッドサーチ)で最適値を決定します。また、モデルに入力する特徴量は、個々のファイルに対する過去の一定期間のアクティビティを用います。たとえば、30分ごとに時間を区切って、それぞれの区間におけるオープン回数を過去60日間にわたって記録すれば、これまでにこのファイルを開く頻度がどのように変化したかという時系列情報が得られます。24(時間)×2×60(日)=2,880ですので、約3,000個の数値で表現される情報です。その他にはファイルの種類(MIMEタイプ)やファイルにアクセスしたクライアントの種類などのカテゴリーデータも使用します。次の図2は、オープン回数だけを用いたベースラインモデルから出発して、特徴量の種類を増やしながら学習状況がどのように改善するかを確認した結果になります。

図2 特徴量の追加による学習状況の改善(論文より抜粋)
ここでは、テストデータに対する誤差関数(予測値と正解ラベルの差を示す指標)の値がどのように減少したかが示されています。先に、ハイパーパラメーターチューニングでニューラルネットワークの構造を決定すると説明しましたが、ハイパーパラメーターチューニングによる改善と比較して、圧倒的に大きな改善が見られたそうです。機械学習全般に言えることですが、モデルの構造よりも、モデルに入力する学習データがより重要であることを示す結果と言えるでしょう。
機械学習モデルを設計する際は、通常は、学習に使用するデータを選定するための「探索的データ分析」を行います。これは、実環境から収集された元データをアナリストが分析して、個々のデータの品質や具体的な内容を確認しながら、学習に有用な特徴量を選定するという作業です。しかしながら、Googleドライブのシステムには、ユーザーのプライバシー保護の仕組みがあり、ユーザー本人以外は個々のドキュメントの内容は見られないようになっています。そのため、ファイルのオープン回数など、匿名化された統計情報だけを用いて学習モデルを作る必要がありました。
この際、得られたデータに不自然な点があるなどした場合、その根本原因が容易には探れないという課題があったそうです。論文内では、次のような具体例が紹介されています。ある一定のユーザー群は、2秒以下という短い時間間隔で複数のファイルを連続して開くという特徴がありました。これが、同一のイベントを異なる経路で重複して記録するといったロギングシステムの問題なのか、クライアントアプリケーションの特殊な挙動なのか、あるいは、本当に連続してファイルを開いているのかが判別できずに苦労したそうです。最終的には、このような挙動を示すのは、画像ファイルに対してのみであり、クライアントアプリケーションが画像イメージをプリロードするためと分かりました。このように、統計処理されたサマリーデータだけが利用できる環境で機械学習モデルの設計をどのように進めるかは、今後の研究課題になるだろうと指摘されています。
上述のプライバシー保護の仕組みについて、論文内に詳しい説明が記載されています。関心の高いポイントだと思いますので、全文を翻訳して紹介しておきます。
「Googleのプライバシーポリシーは、技術者がユーザーデータにそのままの形でアクセスすることを禁止しています。代わりに、匿名化された、統計情報のみを取り扱うことが許されます。これは、ピアレビューを通過したバイナリコードのみがユーザーデータにアクセスできるという仕組みによって実現されています。さらに、ユーザーデータへのすべてのアクセスは、それを実行したバイナリコードのソースコード、および、アクセス実行時のパラメータ値と共に記録されます。プライバシーポリシーを実装するための具体的なインフラの仕組みについては、本論文では取り扱いませんが、このようなプライバシーに配慮した安全策は、開発のスピードを犠牲にするものですが、高い信頼性を持ったデータ保護を実現しています。」
今回は、2017年に公開された論文「Quick Access: Building a Smart Experience for Google Drive」を元にして、Googleドライブの「クイックアクセス」機能に用いられる機械学習モデルについて解説しました。次回は、このモデルを実環境に適用した際に直面した課題や実環境における性能評価の結果を紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































