
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2017年に公開された論文「Quick Access: Building a Smart Experience for Google Drive」を元にして、Googleドライブの「クイックアクセス」機能の開発、特に、表示するファイルを選択する機械学習システムについて解説していきます。
WebブラウザでGoogleドライブにアクセスすると、画面の最上段に「頻繁に開いたドキュメント」「今日編集したファイル」などのメッセージと共に、ユーザーがこの後すぐに利用すると予想されたファイルが表示されます。あるいは、スマートフォンで開いた場合は、ホーム画面に同様のファイルが並びます。これは、「クイックアクセス」と呼ばれる機能で、機械学習モデルによって表示するファイルが選択されています。冒頭の論文では、この機械学習モデルの仕組みとあわせて、本機能の開発における課題や導入の効果を示すデータが紹介されています。今回はまず、クイックアクセスで用いられる機械学習システムについて、その概要を説明します。
オンラインでの業務の作業効率について調査した論文よると、一般に、電子メールへの対応に業務時間の28%が費やされており、それに次いで、業務時間の19%は、業務に必要なファイルやドキュメントといった情報の検索に使われているそうです。Googleドライブのクイックアクセスは、このようなファイルを探す時間を短縮することを目的とした機能です。機械学習の観点では、個々のユーザーが次に必要とする、つまり、クリックして開く可能性が高いファイルを選び出すモデルが必要ということになります。一見すると、動画配信サイトのレコメンデーション機能にも似ていますが、学習対象のデータに大きな違いがあります。
動画のレコメンデーションでは、すべてのユーザーに共通の大量の動画のストックがあり、そこから、個々のユーザーに適した動画を選択することになります。一方、Googleドライブの場合、個々のユーザーは自分が所有するファイルを個別に持っており、この中から自分が必要とするファイルを選択する必要があります。つまり、ユーザーごとに学習対象のデータセットが異なるのです。そこで、クイックアクセスの開発チームは、それぞれのユーザーのアクションログ、つまり、どのファイルにどのような操作(開く、編集するなど)を行ったかというデータをBigtableに蓄積しておき、ここから、ユーザーごとの学習データを生成する仕組みを用意しました。学習データの生成とモデルの学習処理、学習済みモデルの評価、そして、学習済みのモデルによる予測処理、この3つの仕組みをまとめると、図1のようになります。
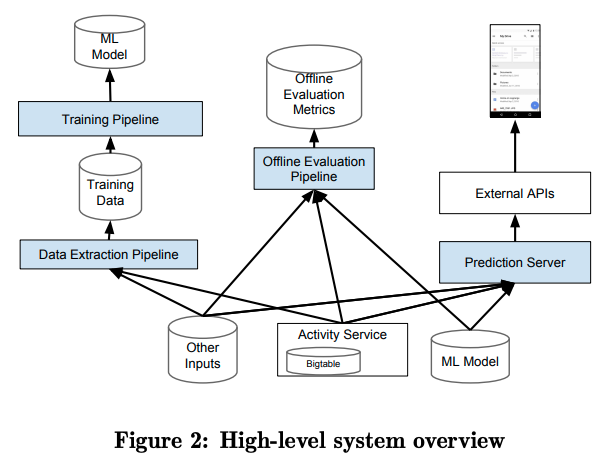
図1 クイックアクセスの機械学習システム概要(論文より抜粋)
図の下部中央にある「Activity Service」は、Bigtableに保存されたユーザーのアクションログを検索・抽出するサービスです。左側の「モデル作成」の部分には、Activity Serviceからデータを抽出して学習データを用意するパイプラインと、それを用いて学習処理を行うパイプラインがあります。中央の「モデル評価」は、学習済みのモデルをオフラインで検証するパイプライン、そして、右側の「予測処理」は、Googleドライブのアプリケーションで、実際の予測処理を行う部分です。
ここで、学習データを生成するパイプラインについて説明します。まず、アクションログの中から、ある特定のファイルを開いた際のユーザー、および、ファイルの情報を予測に使用する特徴量として抽出します。この特徴量に対して正解ラベル「1」を付与したものを1つの学習データとします。さらに、同じユーザーが所有する他のファイルをいくつか選択して、ファイルの情報をこれらに置き換えた上で、正解ラベル「0」を付与したものを学習データに追加します。過去の一定期間に渡るアクションログをスキャンして、このような作業を繰り返すことで、学習データが完成します。特徴量の内容については次回に改めて解説しますが、これらの学習データでモデルを学習すれば、ある状態のユーザーに対して、そのユーザーが所有する任意のファイルを組み合わせて、対応するラベルが「1」である、すなわち、このファイルを開く確率が予測できることになります。
実際の予測処理を行う際は、過去60日間にユーザーが使用したファイルのそれぞれについて、上記の確率を予測して、確率が高いものをクイックアクセスの候補として表示します。この60日という期間は経験的なもので、実際にユーザーが開くファイルの75%以上は、過去60日以内にアクセスしたものであるというデータに基づきます。
前述の学習データ生成パイプラインは、Flume(Cloud Dataflowに類似の分散データ処理サービス)を用いて実装されています。2000CPUコア程度のクラスターで実行されており、数時間のバッチ処理で全ユーザーに対する学習データの生成が行われることが論文内に記載されています。
今回は、2017年に公開された論文「Quick Access: Building a Smart Experience for Google Drive」を元にして、Googleドライブの「クイックアクセス」機能を支える機械学習システムの概要を紹介しました。次回は、機械学習モデルの構成に加えて、開発チームが直面した課題などを紹介します。特に、Googleドライブのシステムには、ユーザーの個人データを守るセキュリティ保護の仕組みがあるため、機械学習モデルを作成するエンジニアは、当然ながら、個々のドキュメントの内容を見ることはできず、匿名化された統計情報だけを用いてモデルを設計する必要があります。このような制限に苦労したという開発チームのエピソードも紹介したいと思います。Googleのプライバシーポリシーの詳細は、次回の記事を参照してください。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































