これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2016年に公開された論文「Slicer: Auto-Sharding for Datacenter Applications」を元にして、Googleが提供するアプリケーションのバックエンドで利用されている「シャーディングシステム」について解説します。今回は、タスクの割り当てを自動調整するシャーディングのアルゴリズムを説明します。
前々回の記事では、シャーディングシステムは、ロードバランサーの機能拡張にあたるものだと説明しました。新しいサービスをSlicerに登録すると、まずはじめは、キーのハッシュ値全体を同じ幅のレンジに等分割して、それぞれを同数のタスクに割り当てます。たとえば、ハッシュ値が「a以上b未満」のレンジはタスク1〜3、「b以上c未満」のレンジはタスク4〜6と言った具合で、それぞれのレンジの幅は同一になります。仮に、それぞれのキーに対するリクエスト数が同じであれば、それぞれのタスクは同数のリクエストを受け取ることになります。
もちろん、現実にはそのようなことはありません。それぞれのキーに対するリクエスト数に偏りがあるため、一部のタスクが多量のリクエストを受け取る、あるいは、CPUやメモリーなどのリソースの使用量が極端に増加するといったことが起こります。このような際に、タスクごとのリクエスト数、あるいは、リソースの使用量をなるべく均等に近づけることがSlicerの役割になります。たとえば、リクエストが多いレンジをさらに細かく分割して、別々のタスクに割り当て直すという方法が考えられます。あるいは、逆に、リクエストが少ない隣接する2つのレンジを結合して、1つのレンジにするという方法もあります。Slicerは、これら2つの方法を用いて、ハッシュ値の分割方法を調整することで、タスクごとの負荷のばらつきを抑えます。
負荷が高いタスクについては、オートスケール機能を用いて、タスク数そのものを増やすという方法もありますが、Slicer自身は、オートスケールの機能は提供しません。あくまで、既存のタスク群に対して、負荷が均等になるようにハッシュ値のレンジを調整することがSlicerの役割になります。Googleのインフラ環境では、第84回の記事で紹介したAutopilotなど、オートスケール機能は別の仕組みで行われるためです。
また、ハッシュ値のレンジを調整する際は、リクエスト数を均等にするのか、もしくは、各タスクのリソース使用量を均等にするのか、どちらかを選択することができます。リソース使用量を均等にする場合は、他のモニタリングシステムと連携して、そちらから取得したリソース使用量のデータを使用します。
そして、ハッシュ値の分割方法を調整するプロセスは、大雑把には次のようになります。まずはじめに、リクエストが少ない近接するレンジを結合して、一方のレンジに割り当てられていたタスクを解放します。次に、リクエストが多いタスクに対して複数のレンジが割り当てられていた場合、一部のレンジをリクエストが少ない(もしくは、レンジの割り当てを持たない)タスクに割り当てなおします。一般に、1つのタスクに対して、複数のレンジが割り当てられることもある点に注意してください。最後に、リクエストが多いタスクに対して、大きな幅のレンジが割り当てられていた場合、このレンジを2つのレンジに分割します。これで、1回の調整プロセスが終了します。最後のレンジ分割処理については、この時点では該当タスクへの負荷は変わりませんが、次の調整プロセスが実行されたタイミングで、分割された一方のレンジが他のタスクに割り当てられることになります。
Slicerは、このような調整プロセスを定期的に実行することで、それぞれのタスクのリクエスト数、もしくは、リソース使用量がなるべく均等に近づくようにします。ただし、キーの割り当てが頻繁に変わりすぎると、タスク内におけるキャッシュデータの再利用など、シャーディングシステムを用いる利点が損なわれます。上述の調整プロセスには、割り当ての変更量が一定以下に収まるように制限をかける仕組みも実装されています。
冒頭の論文では、先ほど紹介したアルゴリズムの性能を示す多数のデータが公開されていますが、ここでは、分かりやすいデータを1つだけ紹介します(図1)。
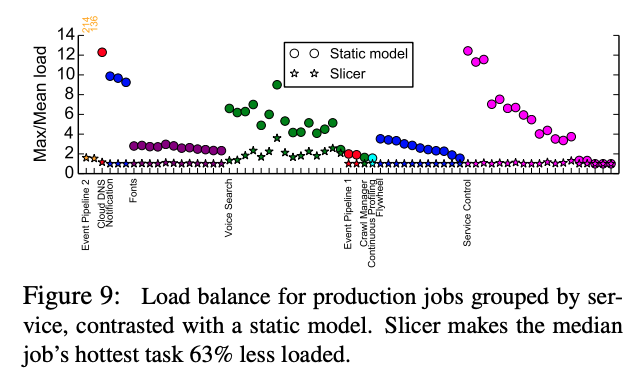
図1 タスクの負荷のばらつきを示すデータ(論文より抜粋)
これは、いくつかのサービスについて、そこに含まれるタスクごとに負荷のばらつきがどの程度あるかを示したものです。ある特定の処理を実行するタスク群があった際に、最も負荷が高いタスクが、タスク群全体の平均値に対して何倍の負荷を持っているかが縦軸の値になります。丸印は、自動調整機能を持たないシャーディングシステムの場合で、星印は、自動調整機能を持ったSlicerの場合の結果になります。これをみると、Slicerによって、タスクごとの負荷のばらつきが抑えられていることが、はっきりとわかります。負荷のばらつきが少ないということは、一部のタスクはリソースが不足して、残りの多数のタスクはリソースが大きく余るといった状況がなく、システム全体のリソースをタスク全体で無駄なく使用できることになります。
今回は、2016年に公開された論文「Slicer: Auto-Sharding for Datacenter Applications」を元にして、Googleが提供するアプリケーションのバックエンドで利用されている「シャーディングシステム」について、タスクの割り当てを自動調整するアルゴリズムを解説しました。
次回は、みなさんもよく利用するGoogle Driveに関連した、機械学習システムの話題をお届けします。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































