
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2016年に公開された論文「Slicer: Auto-Sharding for Datacenter Applications」を元にして、Googleが提供するアプリケーションのバックエンドで利用されている「シャーディングシステム」について解説します。今回は、もう一歩踏み込んだ、より詳細なアーキテクチャーを紹介します。
前回の記事では、Slicerのアーキテクチャーの概要を(前回の記事にある)図2のように示しました。ただし、実際の環境では、クライアント(Clerk、Slicelet)がSlicer Serviceと直接に通信するわけではありません。前回の図1に示したように、秒間200万〜700万リクエストを処理する大規模なシステムですので、クライアントの数は膨大になります。クライアントとSlicer Serviceの通信がボトルネックにならないように、処理を分散化する必要があります。図1は、この点を示したより詳細なアーキテクチャーになります。
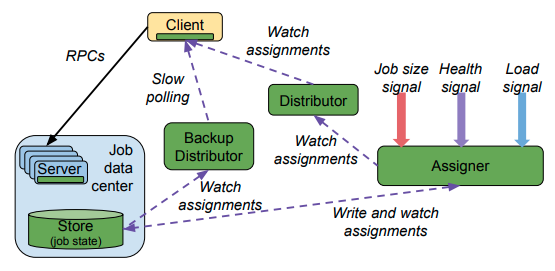
図1 Slicer Serviceからクライアントへの情報配信(論文より抜粋)
この図にある「Assigner」は、Slicer Serviceのメインコンポートネントで、ここで、キーに対するタスクの割り当てを決定します。そして、「Distributor」は、AssignerからClerkやSliceletなどのクライアント(図1の「Client」)にデータを配信する際の中継機能を担います。複数のDistributorが分散配置されており、クライアントは、キーに対するタスクの割り当て情報が必要になると、一番近い場所にあるDistributorに情報を取りに行きます。この際、Distributorは、要求された情報を持っていなければ、Assignerから情報を取得してクライアントに返します。取得した情報は、一定期間キャッシュされるので、これにより、Assignerに対する通信量を削減します。クライアントとDistributorは、通信開始時のセッション確立のオーバヘッドを削減するために、データ通信を行わない時もセッションを保持し続けます。
なお、前回説明したように、(音声認識サービスなどの)特定のジョブ(サービス)におけるすべてのキーは、63bitのハッシュ値に変換された後に、ハッシュ値のレンジごとにタスクが割り当てられます。したがって、割り当て情報全体は、比較的コンパクトに圧縮することができます。特定のキーに対するタスクの情報が個別にやり取りされるわけではなく、1つのジョブにおける割り当て情報全体がまとめてやりとりされる点に注意してください。
ここで、グローバル・ロードバランサーとSlicerの関係を整理しておきます。Googleのネットワークインフラには、「Google Front End」と呼ばれるグローバル・ロードバランサーの機能(正確には、バックエンドに対するロードバランス機能を持ったHTTP proxy)が用意されています。これは、地理的に分散した複数のデータセンターに対するロードバランサー機能を持っており、アクセス元のクライアントに対して、近い位置にあるデータセンターにリクエストを転送することができます。一方、ここで紹介しているSlicerは、基本的には1つのデータセンター内において、キーとタスクの紐付けを行います。つまり、グローバル・ロードバランサーがデータセンターを選択して、その後、Slicerがデータセンター内におけるタスクを選択するという流れになります。
次に、Slicerの耐障害性について見ていきます。まず、冗長化のために、複数のAssignerが同時稼働しており、それぞれが独立にタスクの割り当てを決定します。このため、一時的に、Assignerごとに割り当て情報が異なる可能性がありますが、最終的にはすべてのAssignerが同一の割り当てに至るアルゴリズム(いわゆる「Eventual Consistency」を持つアルゴリズム)が用いられています。
具体的には、それぞれのAssignerは、自身が決定した情報を共有のディスク領域(図1の「Store」)に書き込みます。Assignerが割り当て情報を更新する際は、このディスク領域のデータから他のAssignerによる割り当て結果を参照することで、最終的にすべてのAssignerによる割り当てが同一になるように収束していきます。なお、前回説明したように、Sliceletには、強い整合性を保証するためのAPIが用意されています。このような場合は、特定のAssignerの割り当て情報のみを参照することで、Eventual Consistencyによる一時的な不整合を回避するように設計されています。ただし、実際の運用では、安定的にシステムが動いている状態では、1つのデータセンター内では、1つのジョブに対する割り当て処理は、1つのAssignerのみが行います。このため、基本的には、データセンター内で割り当て情報の不整合が発生することはありません。
また、万一、すべてのAssignerが停止するような障害が発生した場合は、先ほどのディスク領域にその時点での割り当て情報が残っています。図1の「Backup Distributor」は、Assignerではなく、ディスク領域の情報を参照してクライアントに割り当て情報を返すようになっており、Assigner停止時は、クライアントは、通常のDistributorから、Backup Distributorへと通信先を切り替えます。クライアント、Distributor、そして、Assignerは、通常のデータ通信に用いるネットワーク(Data plane)とは異なる、専用の管理系ネットワーク(Control plane)を介して通信を行います。これにより、Slicerを構成する各コンポーネントは、通常のデータ通信ネットワークの負荷に影響されず、安定した通信を行うことができます。
今回は、2016年に公開された論文「Slicer: Auto-Sharding for Datacenter Applications」を元にして、Googleが提供するアプリケーションのバックエンドで利用されている「シャーディングシステム」について、より詳細なアーキテクチャーを紹介しました。次回は、引き続き、タスクの割り当てを決定するアルゴリズム、そして、Slicerによる性能向上を示すデータなどを紹介していきたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































