これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2016年に公開された論文「Slicer: Auto-Sharding for Datacenter Applications」を元にして、Googleが提供するアプリケーションのバックエンドで利用されている「シャーディングシステム」について解説します。以前はアプリケーションごとに個別の仕組みを作り込んでいましたが、効率のよいシャーディングシステムを開発するのはそれほど簡単ではありません。そこで、複数のアプリケーションから利用できる共有型のシャーディングシステムとして、「Slicer」が開発されました。現在では、Speech Recognition(音声認識)やCloud DNSなど、さまざまなサービスのバックエンドとして、1秒あたり200万〜700万リクエストを処理するシステムになっているそうです。
ここで説明するシャーディングシステムは、クライアントからのアクセスを複数のアプリケーションサーバーに分配するロードバランサーの機能拡張にあたります。なお、Googleの環境では、アプリケーションサーバーの機能は、コンテナ管理システムであるBorgの「タスク」として稼働します。これ以降は、アプリケーションサーバーの代わりに「タスク」という用語を使用します。
たとえば、先ほど挙げた音声認識サービスの場合は、さまざまな言語に対応する必要があり、各タスクは、言語ごとに専用のモジュールをメモリにロードします。ただし、メモリの使用量を最適化するために、すべてのモジュールを同時にロードするのではなく、タスクごとに異なるモジュールをロードしておき、英語のリクエストは、英語のモジュールをロードしたタスクにルーティングするといった処理を行います。仮に、英語のモジュールをロードしていないタスクに英語のリクエストが来た場合、リクエストを処理する前に(既存のモジュールを破棄して)英語のモジュールをロードしなおす処理が必要になり、リクエストに対する応答時間が長くなります。言語の種類をキーにして対応するタスクを選択することで、このような性能劣化を防ぐのがシャーディングシステムの役割です。
この際、言語の種類によって、クライアントからのアクセス数は大きく異なります。あるいは、時間帯による変動もあるでしょう。そのため、言語ごとにリクエストをルーティングするタスク数を動的に変化させる必要があります。Slicerでは、リクエスト数の増減に応じてタスク数を変化させる他に、タスクのリソース使用量(CPU使用率など)によってタスク数を変化させるといったカスタマイズも可能です。
音声認識サービスの他にも、メモリ上にキャッシュされたデータを使用するサービスの場合、同一の種類のリクエストを同じタスクに割り当てれば、以前に処理した際のキャッシュデータを再利用して処理を高速化することができます。冒頭の論文では、このようなキャッシュの有効利用のためにシャーディングシステムを使用している実サービスの例がいくつか紹介されています。Slicerは、独自のアルゴリズムでタスク数を調整しており、これらのサービスでは、(自動調整機能を持たない)固定的なシャーディングに比べて、リソース使用量が(中央値で)63%削減されたそうです。
冒頭でも触れたように、Slicerは、現在、秒間200万〜700万リクエストを処理しており、実際の処理数を示すグラフは図1のようになります。
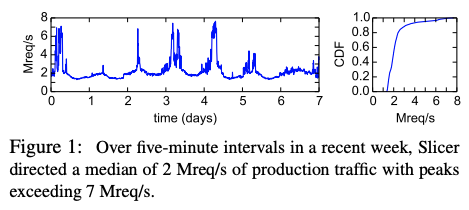
図1 Slicerによるリクエスト処理数(論文より抜粋)
Slicerのアーキテクチャーについて、まずは、その概要を説明します。全体の仕組みは、図2のようになります。
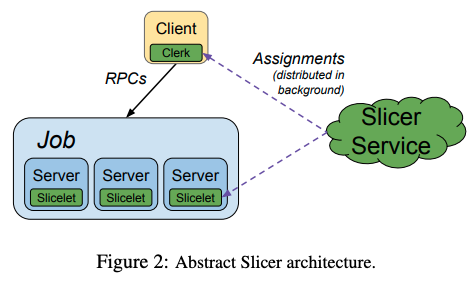
図2 Slicerのアーキテクチャー概要(論文より抜粋)
図の右側にある「Slicer Service」がそれぞれのキーに対応して割り当てるタスクを決定します。キーに使用するデータはアプリケーションごとに任意に決めることができて、音声認識サービスであれば言語コードがキーになります。その他には、ユーザー名やURLなどをキーとするアプリケーションもあります。Slicer Serviceは、このような様々なキーを63bitのハッシュ値に変換した後、ハッシュ値のレンジごとに、割り当て先のタスクを決定します。レンジの幅を大きくすれば、1つのタスクが担当するキーの個数も増えることになります。
次に、クライアントに埋め込まれたライブラリーモジュール「Clerk」は、タスクの割り当て情報をSlicer Serviceから取得して、リクエストを送信するべきタスクを決定します。クライアント上のアプリケーションは、ClerkのAPIで直接に宛先となるタスクを検索することもできますが、通常は、そのような作り込みは不要です。Googleでは、クライアント・サーバー間の通信プロトコルとして、gRPC、もしくはそれに類似の独自プロトコル(Stubby)を使用しており、これらは、自動的にClerkと連携するように作られています。つまり、これらのクライアントライブラリーは、ClerkのAPIを用いて、自動的にリクエストを送信するタスクを決定します。一般には、1つのキーに対して複数のタスクが得られるので、これらに対してさらに負荷分散を行います。
一方、リクエストを受けるタスクの方にも、ライブラリーモジュール「Slicelet」が配置されています。Slicerではタスクの割り当てが動的に変化しますが、クライアント側のClerkが割り当ての変更を認識するまでに遅延が生じたり、あるいは、タスクがリクエストを処理している途中に割り当てが変化するといった事象が発生します。一般には、このような遅延や処理中の変更は問題となるものではありませんが、サービスの種類によっては、「特定のキーに対する処理は、一時点において、かならず、1つのタスクだけで処理する必要がある(クライアントによってリクエストを送信するタスクが変化しては困る)」という強い整合性が求められることがあります。このようなサービスでは、1つのキーに対応するタスクを1つだけに制限した上で、さらに、SliceletのAPIを用いると、クライアントから送信されたリクエストが、今現在、確かに自分に割り当てられたものであるのか、あるいは、リクエストの処理中に割り当てが変化しなかったか、などの情報を確認することができます。
今回は、2016年に公開された論文「Slicer: Auto-Sharding for Datacenter Applications」を元にして、Googleが提供するアプリケーションのバックエンドで利用されている「シャーディングシステム」について、そのアーキテクチャーの概要を紹介しました。次回は、タスクの割り当てを動的に決定するアルゴリズムなど、より詳細な仕組を解説した上で、Slicerによる性能向上を示すデータなども紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































