
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2020年に公開された論文「Dremel: A Decade of Interactive SQL Analysis at Web Scale」を紹介していきます。論文のタイトルある「Dremel」は、Google社内のデータ分析ツールの名称で、Google Cloud Platformで提供されているBigQueryは、このDremelが元になっています。
Dremelのアーキテクチャーは、2010年の論文「Dremel: Interactive Analysis of Web-Scale Datasets」で初めて紹介されましたが、その後もさまざまな変化を続けています。冒頭の論文では、その後の10年間に起きたアーキテクチャーの変化を踏まえた上で、現在のDremelの特徴を次の5つの観点から説明しています。
・ANSI準拠のSQL
・計算リソースとストレージリソースの分離
・In situ(イン・サイチュ)分析
・サーバーレスシステム
・カラム型ストレージ
今回は、「ANSI準拠のSQL」と「計算リソースとストレージリソースの分離」の2つについて解説を進めます。
Googleでは、大規模なデータを取り扱うさまざまな技術を開発してきましたが、2000年代の初期に主に用いられたのは、分散ファイルシステムのGFS(Google File System)とMapReduceを組み合わせた方式でした。また、NoSQLストレージであるBigtableもこの頃から利用が広がりました。これらは、SQLを使用しないことで、数千台規模のサーバーによる並列処理を可能にするという特徴があり、これらのアーキテクチャーを紹介した論文がきっかけとなり、Google以外の企業においても、オープンソースのHadoopやその他のNoSQLシステムの利用が広がりました。当時のGoogle社内では、「SQLを利用するシステムはスケールしない」というのが基本的な考え方でした。
しかしながら、これらには、システム内部に関する専門的な知識を持たないアナリストが容易に利用できると言うSQLのメリットが欠けていました。そこで、SQLを利用して大規模データの分析を行うツールとして、Dremelが開発されました。DremelはシンプルなSQLでデータ分析が行えるため、SQLを少しずつ修正しながら対話的に分析を進めることができます。MapReduceのアルゴリズムを直接に実装する場合と比べると、分析作業の効率が格段に向上したのです。そしてまた、Dremelの成功をきっかけにして、Google社内では、SQLの利用が徐々に見直されていき、Dremelの他にもSQLを利用したシステムの開発が進められるようになりました。分散RDBのSpannerは、その中でも特によく知られた例といえるでしょう。
ただし、これらのシステムは、それぞれのユースケースに応じた独自のSQL構文を採用しており、システムによってSQL文の互換性がないという問題が生まれました。この問題を解決するために、Google社内では、「GoogleSQL」プロジェクトが立ち上がりました。これは、ANSI準拠のSQL構文に独自の拡張を加えた「Google標準のSQL」を定義した上で、SQL文のパーサー(構文解析)などの共通機能を標準ライブラリとして実装するというものです。これらのライブラリを用いることで、複数のシステムで共通のSQL構文が利用できるようになりました。また、これと並行して、Dremel自体の機能も拡張されていきました。この後で説明する「シャッフルアーキテクチャー」の導入により、これまでよりも複雑なJoinが実行可能になりました。
冒頭の論文によると、Dremelは、あるソフトウェアエンジニア個人の「20%プロジェクト」として、2006年に開発がスタートしました。当初は、専用のサーバークラスターを用意して、それぞれのサーバーのローカルディスクに処理対象のデータを配置するというアーキテクチャーを用いていましたが、システムの規模が大きくなるにつれて、専用のサーバーを管理することが困難になりました。そこで、2009年にGoogle社内標準のクラスター管理システムであるBorgにシステムを移行しました。これにより独自のクラスターを管理する必要はなくなりましたが、Borg上で稼働するシステムは、ローカルに永続データを配置する「ステートフル」な実装ができません。そこで、処理対象のデータをGFSに保存しておき、ネットワーク経由でGFS上のデータにアクセスするというアーキテクチャーに変更しました。
この新しいアーキテクチャーには、メリットとデメリットがありました。計算リソースとストレージが分離されたことにより、データの配置を意識せずに計算リソースをスケールアウトできることに加えて、GFSは社内標準の安定した共有サービス(マネージドサービス)であることから、Dremelをより安定的に運用できるというメリットが得られたそうです。一方、ネットワーク経由のデータアクセスによる性能の劣化は大きな課題となりました。これについては、データセンターネットワークの性能向上に加えて、データのフォーマットや配置方式を含めたさまざまなチューニングで改善を図りました。次回説明するように、現在では、Dremelに最適化されたカラム型ストレージのシステムも導入されています。
Dremelのアーキテクチャーの改善は、この後も続けられました。2012年には、GFS上のデータは、より性能の高い、新しい分散ファイルシステムであるColossusに移行しました。そして、2014年には、「シャッフル処理」をオンメモリーで実行する専用のシステムが導入されました。シャッフル処理は、MapReduceを始めとするさまざまな分散データ処理で広く利用される仕組みで、Dremelの場合は、テーブルを結合するJoinの実行に必要となります。これを専用にチューニングされたシステムで実行することにより、より大規模なJoinが高速に実行できるようになったのです。図1は、現在のBigQueryのアーキテクチャーを説明したものですが、計算用のサーバークラスターとデータ保存用のストレージクラスター、そしてその間には、シャッフル専用のシステムが描かれていることが分かります。このアーキテクチャーは、ここで完成したというわけです。
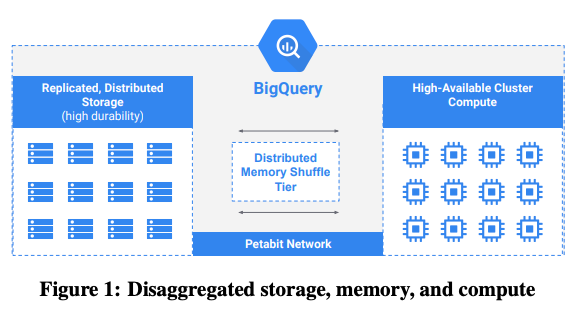
図1 BigQueryのアーキテクチャー(論文より抜粋)
今回は、2020年に公開された論文「Dremel: A Decade of Interactive SQL Analysis at Web Scale」を元にして、現在のDremelのアーキテクチャーの特徴を2つ紹介しました。次回も引き続き、Dremelのアーキテクチャーを紹介していきたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































