これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2020年に公開された論文「Dremel: A Decade of Interactive SQL Analysis at Web Scale」を紹介していきます。論文のタイトルある「Dremel」は、Google社内のデータ分析ツールの名称で、Google Cloud Platformで提供されているBigQueryは、このDremelが元になっています。
前回の記事でも触れたように、この論文では、2010年以降のDremelのアーキテクチャーの変化を紹介しており、現在のDremelの特徴を次の5つの観点から説明しています。
・ANSI準拠のSQL
・計算リソースとストレージリソースの分離
・In situ(イン・サイチュ)分析
・サーバーレスシステム
・カラム型ストレージ
今回は、「In situ(イン・サイチュ)分析」と「サーバーレスシステム」の2つについて解説します。
In situ分析というのは、分析専用のデータベースにデータをアップロードして分析するのではなく、他のアプリケーションが使用する既存のデータをそのままの形で分析するという考え方です。特にGoogle社内には、MapReduceなど、さまざまなデータ処理ツールがあります。たとえば、MapReduceが出力したデータをそのままの形で分析できれば、膨大なデータをアップロードする時間を節約することができます。これを実現するため、Dremelの開発チームは、Dremelが使用するデータのフォーマットを標準化して、このフォーマットのデータを読み書きするためのライブラリーを社内で公開しました。MapReduceのジョブをコーディングする際に、このライブラリーを使用してデータを読み書きするようにすれば、MapReduceが出力したデータをそのままDremelで分析できるだけではなく、Dremelで分析中のデータを読み込んで、MapReduceで再処理する事も容易になります。冒頭の論文によると、これをきっかけとして、Google社内のさまざまなデータ分析ツールが互いにデータを共有して連携するという流れが大きく広がったということです。
さらに、Dremelは、この標準フォーマットに加えて、Avro、CSV、JSONといった既存のデータフォーマットにも対応しました。これらのデータを分析する場合、内部的にフォーマットの変換が行われるためにI/O処理のオーバーヘッドが発生します。しかしながら、Google社内での利用状況を見ると、自分で標準フォーマットに変換する手間を省くために、オーバーヘッドに伴う性能上の制約を受け入れるというユースケースも多数あるということです。このように、Google社内では、それぞれのプロジェクトが自分たちに適した方法で、独自のデータを管理して、Dremelとの連携を図っています。
一方、Dremel専用のデータ保存領域を用意するという従来の管理方法にもメリットがあります。たとえば、データ保存領域にデータをアップロードする際にデータの統計値を取得して、検索処理の最適化に利用することができます。あるいは、プロジェクトによっては、Dremelで分析するデータを自分たちで管理するのではなく、Dremel専用の領域に安全に保管しておき、スキーマ変更などの作業は、Dremelの機能で簡単に行いたいという場合もあるでしょう。このため、Google Cloud Platformで提供されるBigQueryでは、ユーザー自身でデータを管理する必要のない、BigQuery専用のデータ保存領域が標準で用意されています。
オンプレミスのRDBシステムでは、アプリケーションごとに専用のデータベースシステムを用意することがほとんどですが、MapReduceやHadoopといった大規模データの分析システムでは、複数のプロジェクトが共有して利用するマルチテナント型の構成が一般的です。特にDremelの場合は、前回の図1に示したように、計算リソースとストレージが分離されているため、マルチテナント型の構成が容易です。Dremelのジョブスケジューラーは、分析のジョブごとに必要なリソースを柔軟に割り当てることができます。また、1つの分析ジョブを多数のサブタスクに分解して実行しますが、個々のタスクは「冪等性」を持っており、ハードウェア障害などで処理が失敗した際にも簡単に再実行ができます(図1)。つまり、一部のタスクが失敗しても、ジョブ全体を一から再実行する必要がありません。
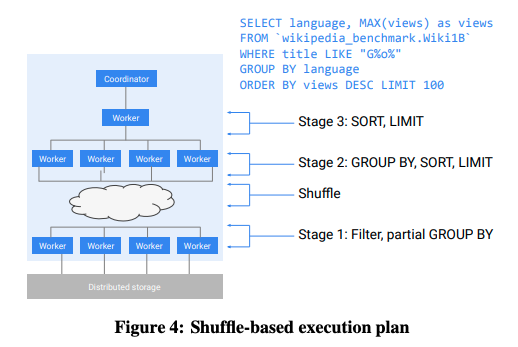
図1 複数のワーカーが連携してジョブを実行する仕組み(論文より抜粋)
さらに、ジョブの実行を高速化するためのさまざまな最適化が行われます。たとえば、同一のタスクを複数のワーカーに割り当てて、最初にタスクが完了したワーカーの結果を利用します。これにより、一部のワーカーの実行速度が何らかの理由で極端に低下しても、そのワーカーによってジョブ全体の処理が遅れることが防止できます。あるいは、ジョブの実行中にデータの統計値を取得して、SQLの実行計画をダイナミックに変更するという機能があります。たとえば、2つのテーブルをJoinする際に、両方のテーブルのデータをソートするアルゴリズムAと、一方のテーブルだけをソートするアルゴリズムBがあり、どちらのアルゴリズムが有利かは、テーブルに保存されたデータの構成によって変わるとします。この場合、まずは、アルゴリズムAを使用することを想定して両方のテーブルのソート処理を開始します。ところが一方のテーブルのソートが先に完了して、その時点でアルゴリズムBの方が有利だと分かれば、他方のテーブルのソートをキャンセルして、アルゴリズムBに処理を切り替えます。Dremelが扱う大規模データの場合、テーブルに含まれるデータの構成を事前に調べるのが難しいため、このように、SQLの実行中に必要な統計情報を取得するというテクニックが有効になります。
今回は、2020年に公開された論文「Dremel: A Decade of Interactive SQL Analysis at Web Scale」を元にして、前回に続けて、現在のDremelのアーキテクチャーの特徴を2つ紹介しました。次回も引き続き、Dremelのアーキテクチャーを紹介していきます。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































