
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2020年に公開された論文「Dremel: A Decade of Interactive SQL Analysis at Web Scale」を紹介していきます。論文のタイトルある「Dremel」は、Google社内のデータ分析ツールの名称で、Google Cloud Platformで提供されているBigQueryは、このDremelが元になっています。
パート1で触れたように、この論文では、2010年以降のDremelのアーキテクチャーの変化を紹介しており、現在のDremelの特徴を次の5つの観点から説明しています。
・ANSI準拠のSQL
・計算リソースとストレージリソースの分離
・In situ(イン・サイチュ)分析
・サーバーレスシステム
・カラム型ストレージ
今回は、最後の1つとなる「カラム型ストレージ」について解説します。
Googleでは、さまざまなアプリケーションの標準データフォーマットとして、Protocol bufferを採用しています。サーチエンジンやGMailをはじめとするすべてのアプリケーションで用いられており、gRPCを用いたサービス間のデータ交換でもProtocol bufferが利用されます。そして、Dremelのテーブルに保存するデータにも、Protocol bufferをベースにしたスキーマが適用されます。一般的なデータベースとは異なり、Dremelのテーブルでは、「ネストされた列(nested columns)」や「繰り返し列(repeated columns)」が利用できますが、これは、Protocol bufferのデータ構造に由来するものです。
ただし、Dremelの内部では、このようなデータをそのままの形でストレージに保存するわけではありません。SQLでの検索に適したフォーマットに変換した上でストレージに格納しており、この部分においてもアーキテクチャーの進化がありました。論文の中では、2014年に「Capacitor」と呼ばれる新しいフォーマットのカラム型ストレージが導入され、既存データの移行が始まったことが説明されています。
Capacitorでは、さまざまな最適化のテクニックが利用されていますが、その中の1つに、「行の並べ替え」があります。図1はその一例を示すものですが、左端のテーブルのデータを中央のテーブルのように行を並べ替えます。すると各列のデータの並びに規則性が生まれるので、右端のテーブルのように容易にデータを圧縮することができます。

図1 行の並べ替えによるデータ圧縮最適化の例(論文より抜粋)
この例だけを見ると簡単な仕組みに思えますが、実際には、これを数百万行、あるいは、場合によっては数億行ものデータに適用する必要があります。これほどの膨大なデータに対して、真に最適な並べ替え方法を発見するのは現実的ではありませんので、データのサンプリング、あるいは、各行へのアクセス頻度などを考慮して、現実的なスピードでより最適に近い並べ替え方法を見つけ出すアルゴリズムが実装されています。図2は、いくつかのデータセットに対して、実際の圧縮率を測定した結果になりますが、平均的に17%程度、データセットによっては、70%以上の圧縮率が実現されています。
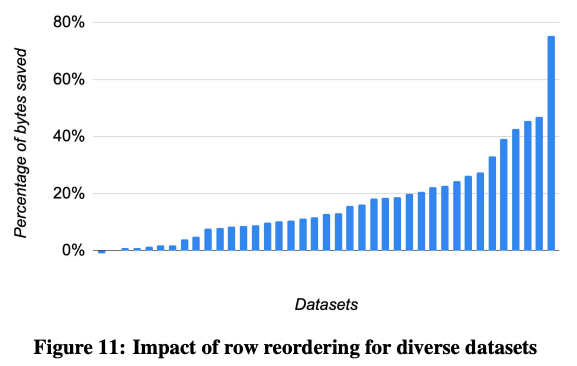
図2 行の並べ替えによるデータ圧縮率の測定結果(論文より抜粋)
なお、前回の「In situ分析」で説明したように、Dremelには、Avro、CSV、JSONなど複数のデータフォーマットが扱えるという特徴があります。Capacitorは、あくまで、Protcol bufferをベースとしたDremel標準のデータフォーマットに最適化された仕組みになりますが、現在は、その他の複数のフォーマットにも対応できる、さらに新しいストレージの研究も活発に進められているそうです。
ここまで、Dremelのアーキテクチャーの特徴について、5つの観点から説明してきました。論文の中では、この他にも大規模データに特化した最適化のテクニックがいくつか紹介されています。その中の1つに「Approximate result」という機能があります。大規模データに対してデータ全体の平均値などの統計値を取得する場合、分析の目的によっては、必ずしも厳密な値が必要というわけではありません。この機能を用いると、データ全体の一定割合を処理した時点での近似値を取得することができます。この際、処理するデータの割合は、ユーザーが指定することができます。
大規模な分散データ処理システムでは、ごく一部のデータに対する処理時間が極端に長くなり、全体の性能に大きな影響を与えることがあります。これは逆に言うと、ごく一部の遅い処理をスキップすることで、全体の性能を大きく向上できる可能性があることになります。実際の所、処理対象のデータ量を98%に指定することで、検索速度が2〜3倍に向上することもあるそうです。これは、図3のデータからも理解することができます。
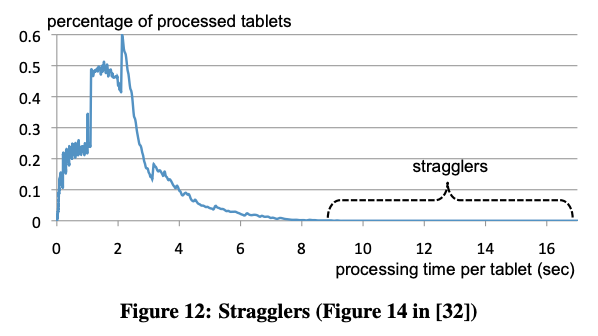
図3 データ処理時間の分布例(論文より抜粋)
このグラフは、ある特定の検索処理におけるタブレット(データの分割単位)ごとのデータ処理時間の分布を示します。大部分のデータは5〜6秒以内に処理が終わっていますが、ごく一部、10秒以上の時間がかかっているものもあります。「stragglers」と示された、これらの処理結果を待たずに検索を打ち切ることで2倍以上の性能向上が得られると言うわけです。
今回は、2020年に公開された論文「Dremel: A Decade of Interactive SQL Analysis at Web Scale」を元にして、前回に続けて、現在のDremelのアーキテクチャーの特徴を紹介しました。
次回は、ネットワークのトラブルシューティングでお馴染みのツール "traceroute" に関連した話題をお届けしたいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































