
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、複数のデータセンターに跨るOpenStack環境を構築する際に必要となる、「リージョン」と「アベイラビリティゾーン」について解説します。日本企業では、複数の国内データセンターを活用することも多いようですが、OpenStackを使用することで、「複数のデータセンターをあたかも1つのデータセンターであるかのように利用したい」という希望を耳にすることがあります。
もちろん、データセンター間を高速なネットワーク回線で接続しておいて、複数データセンターのサーバーを無理矢理に同じデータセンター内のサーバーと見立てて、OpenStack環境を構築することは可能です。しかしながら、現実は、それほど簡単ではありません。たとえば、仮想マシンインスタンスにブロックボリュームを接続した場合、仮想マシンインスタンスとブロックボリュームのバックエンドストレージが異なるデータセンターにあったらどうなるでしょうか? データセンター越えのストレージアクセスでは、性能上の問題が発生するのは目に見えています。
現在の技術では、データセンターの存在をまったく意識させないクラウドの構築は、まだまだ困難です。AWSのパブリッククラウドサービスにおいても、リージョン、および、アベイラビリティゾーンという、データセンターの場所を意識した概念があることを思い出すとよいでしょう。OpenStackで複数データセンターに跨るクラウドを構築する場合も、これと同じく、リージョン、および、アベイラビリティゾーンの考え方を利用します。リージョンとアベイラビリティゾーンを混在した構成も可能ですが、まずは、どちらか一方だけを使用した場合の構成について、その概要を解説したいと思います。
リージョンを使用した構成は、それほど複雑なものではありません。基本的には、データセンターごとに独立したOpenStackの環境を構築します。この時、それぞれのデータセンターの環境に、ユニークなリージョン名を指定しておきます。「TokyoRegion」「OsakaRegion」など、データセンターの場所を表すリージョン名を想像すると分かりやすいでしょう。
そして、ユーザー認証に使用するKeystoneだけは、すべてのデータセンターで共通のものを使用します。Keystoneには、ユーザー情報に加えて、それぞれのリージョンを管理するコントローラーのアドレス(APIのURL)が登録されており、このクラウドを利用するエンドユーザーは、リージョン名を指定してコマンドを実行します。すると、指定したリージョンに対するAPIのURLをKeystoneから取得して、そちらのコントローラーに命令が発行されます。
このようなリージョン構成を用いる場合、Keystoneのサーバーをどのデータセンターに配置するかに注意が必要です。一般に、複数のデータセンターを利用する場合は、災害などで特定のデータセンターが停止した場合に、他のデータセンターで業務を継続するといった使い方が想定されます。Keystoneが稼働するデータセンターが停止した際に、すべてのデータセンターのOpenStackが使用できなくなることは避ける必要があります。
これに対応するには、複数のデータセンターにKeystoneを配置して、バックエンドのデータベースを複数データセンター間でクラスタリングする方法が考えられます。Keystoneそのものは、スケールアウト型のアーキテクチャーになっていますので、エンドユーザーは任意のデータセンターのKeystoneにアクセスして使用することが可能です。ただし、それぞれのKeystoneは、同じデータベースを使用する必要があります。たとえば、MySQLの「Galera Cluster」を使用すると、Active-Active型のクラスターが構成できますので、図1のように複数データセンターのKeystoneで、データベースの内容を共有することが可能になります。Keystoneが使用するデータベースだけを分離して、クラスタリング構成にする点に注意してください。
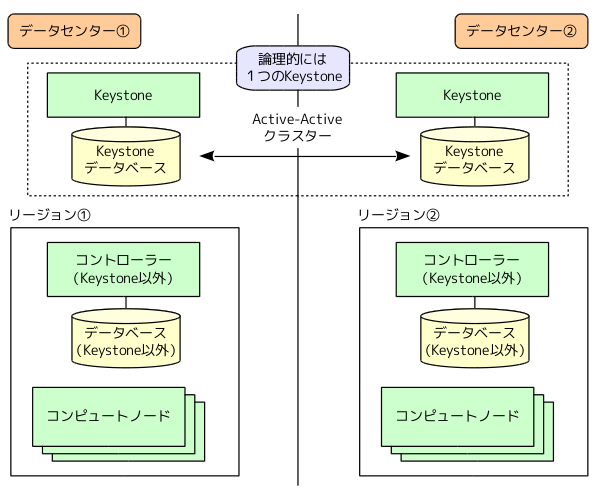
図1 リージョン構成でのコンポーネント配置
なお、リージョン構成の場合、それぞれのデータセンターのOpenStackは独立した環境になりますので、データセンター間でリソースを共有することはできません。仮想マシンインスタンスの起動に使用するテンプレートイメージなどは、デーテセンターごとに個別に管理する必要があります。仮想ネットワークについても、データセンターごとに独立したネットワークが構成されることになります。
アベイラビリティゾーンを使用した構成では、データセンターごとにコントローラーが別れる形にはなりません。1つのコントローラーで、複数データセンターのコンピュートノードをまとめて管理します。この際、同じデータセンター内のコンピュートノードを1つの「アベイラビリティゾーン」としてグループ化しておきます。エンドユーザーは、仮想マシンインスタンスを起動する際に、アベイラビリティゾーンの名前によって、仮想マシンインスタンスを起動するデータセンターを指定します。
また、仮想マシンインスタンスに接続するブロックボリュームのバックエンドストレージもアベイラビリティゾーンに分割することが可能です。エンドユーザーは、ブロックボリュームを作成する際に、アベイラビリティゾーンを指定することで、どのデータセンター内のストレージ装置を使用するかを指定します。その後、仮想マシンインスタンスにブロックボリュームを接続する際は、同じデータセンター(アベイラビリティゾーン)にあるブロックボリュームを選んで接続します。
アベイラビリティゾーンを使用する場合の課題は、コントローラーとそのバックエンドデータベースをデータセンター間でどのように配置するかという点になります。特定のデータセンターだけにコントローラーを配置すると、そのデータセンターが停止した際に、すべての環境が利用できなくなります。たとえば、リージョン構成におけるKeystoneと同様に、複数データセンターにコントローラーを配置して、データベースは、Active-Active型のクラスターに構成する方法が考えられます(図2)。クラスタリングの影響でデータベースの性能が十分にでない場合は、Active-Stanby型のクラスターを検討する必要もあるでしょう。
その他には、Glanceが管理するテンプレートイメージも、何らかの方法でデーテセンター間で複製しておく必要があります。典型的には、複数データセンターにまたがって構成したSwift(オブジェクトストレージ)に保存する形になります。
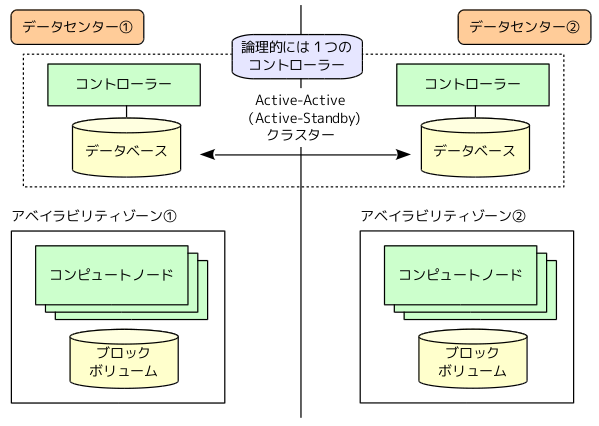
図2 アベイラビリティゾーン構成でのコンポーネント配置
最後に、アベイラビリティゾーン構成の最大の課題は、仮想ネットワークの構成になります。Neutron標準のOpen vSwitchプライグインは、仮想ルーターを配置するネットワークノードが1つしかありませんので、仮想ルーターを経由する通信は、すべて、ネットワークノードを配置したデータセンターまで回ってくることになります。これは、現実的な構成とは言えませんので、仮想ネットワークについては、前回紹介したような、分散型の仮想ネットワークを提供するプライグインの使用が必要となります。
今週は、「G-Tech 2014/Tokyo」と「Red Hat Forum 2014/Tokyo」の2つのセミナーでの講演を予定しています。次回は、これらのセミナーから、新しい情報をお伝えしたいと思います。
++ CTC教育サービスから一言 ++
このコラムでLinuxや周辺技術の技術概要や面白さが理解できたのではないかと思います。興味と面白さを仕事に変えるには、チューニングやトラブルシューティングの方法を実機を使用して多角的に学ぶことが有効であると考えます。CTC教育サービスでは、Linuxに関する実践力を鍛えられるコースを多数提供しています。興味がある方は以下のページもご覧ください。
CTC教育サービス Linuxのページ
http://www.school.ctc-g.co.jp/linux/

| 筆者書籍紹介 Software Design plusシリーズ 「独習Linux専科」サーバ構築/運用/管理 ――あなたに伝えたい技と知恵と鉄則 本物の基礎を学ぶ!新定番のLinux独習書 中井悦司 著 B5変形判/384ページ 定価3,129円(本体2,980円) ISBN 978-4-7741-5937-9 詳しくはこちら(出版社WEBサイト) |
 |
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































