
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2025年に公開された論文「Necro-reaper: Pruning away Dead Memory Traffic in Warehouse-Scale Computers」に基づいて、Googleの研究者が考案した、CPUのキャッシュメモリの処理効率を上げる仕組み「Necro-reaper」を解説します。今回は、Necro-reaperの有効性を示す評価結果を紹介します。
Necro-reaperは、既存のCPUでは未実装のインストラクションを前提にしているので、論文では、オープンソースソフトウェアのシミュレーター(DrCacheSim)によるシミュレーション結果が報告されています。図1に示した、Googleのデータセンターで稼働する10種類のワークロードについて、コード実行時のインストラクションのトレースを評価対象のデータとしています。
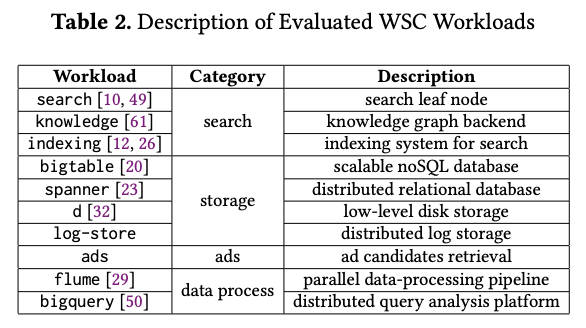
図1 Necro-reaperの評価対象のワークロード(論文より抜粋)
次の図2は、これらのワークロードにNecro-reaperを適用することで、メインメモリとキャッシュメモリの間のデータ転送量がどの程度削減されたかを示す結果です。
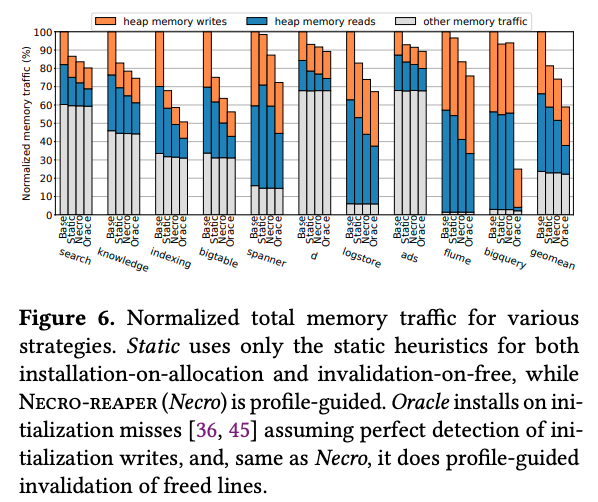
図2 メインメモリとキャッシュメモリの間のデータ転送量の比較(論文より抜粋)
図2の「Base」は最適化を適用しない場合の結果で、残りの3つは、これを100%とした時の相対値になります。「Necro」がNecro-reaperを適用した場合の結果です。「Static」と「Oracle」は、参考として、次の条件による最適化を適用した場合の結果になります。
「Oracle」は、現実にはあり得ない結果ですが、プロファイルデータによる予測のベストケースとして参照することができます。また、グラフの内訳は次の様になります。
図2の結果を見ると、いずれのワークロードにおいてもNecro-reaperによるメモリアクセス量の削減効果が見られます。また、bigqueryを除いて、プロファイルデータを用いないよりも、プロファイルデータを用いた方がメモリアクセス量の削減効果が大きいこともわかります。bigqueryでプロファイルデータの効果が無い点については、コード全体に対して、プロファイルデータが取得できた割合が小さい点が原因として指摘されています。
そして、次の図3は、メモリアクセスのボトルネックがNecro-reaperで解消される効果を示す結果です。ここでは、最適化を適用しない場合に比べた、IPC(CPUサイクルあたりのインストラクション実行数)の増加割合が示されています。メモリアクセス量が削減されることにより、メモリアクセス待ちでインストラクションが実行できないタイミングが減少し、結果として、IPCが増加するものと考えられます。
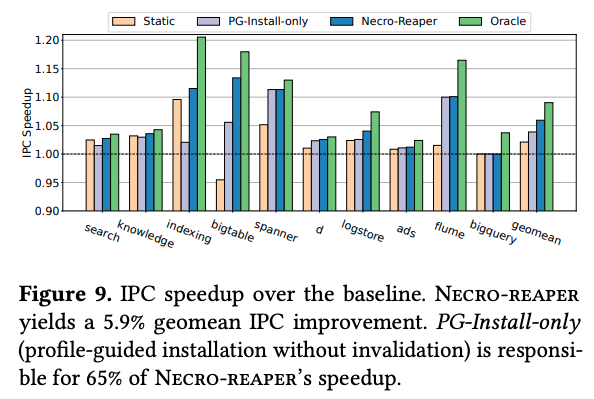
図3 IPC(CPUサイクルあたりのインストラクション実行数)の比較(論文より抜粋)
図3の「Static」「Necro-reaper」「Oracle」は、図2の説明と同じです。「PG-Install-only」は、Necro-reaperからキャッシュ解放の最適化を省いた場合の結果です。図2と図3の結果を総合すると、これら10種類のワークロードに対して、メモリ転送量は(幾何平均で)26%の削減、IPCは(幾何平均で)6%の向上が得られたことになります。
冒頭で触れた様に、Necro-reaperは、既存のCPUでは未実装のインストラクションを前提にしており、いますぐに利用できるわけではありませんが、論文の中では、既存のCPUにこれらのインストラクションを実装する際の設計方針やセキュリティリスクの回避方法なども議論されています。この論文で示された有効性を考えると、近い将来、Necro-reaperが利用可能なCPUが実現する可能性も十分に期待できそうです。
今回は、2025年に公開された論文「Necro-reaper: Pruning away Dead Memory Traffic in Warehouse-Scale Computers」に基づいて、CPUのキャッシュメモリの処理効率を上げる仕組み「Necro-reaper」について、その有効性を示す評価結果を紹介しました。
次回は、大規模言語モデルによるコードマイグレーションに関する話題をお届けします。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































