
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2025年に公開された論文「CoDA: Agentic Systems for Collaborative Data Visualization」に基づいて、データの可視化処理をマルチエージェントで実行するアーキテクチャー「CoDA(Collaborative Data-visualization Agents)」を紹介していきます。今回は、マルチエージェントの考え方と CoDa のアーキテクチャーを説明します。
はじめに、一般的なマルチエージェントのアーキテクチャーを簡単に説明します。いわゆる「AIエージェント」は、大規模言語モデル(LLM)の推論機能を利用して、指定されたタスクを自律的に実行するシステムです。この時、与えられたタスクを複数のサブタスクに分解して、サブタスクごとに専用のエージェントを用意するのがマルチエージェントのアーキテクチャーです。下記のブログ記事では、「リサーチエージェント」「ライターエージェント」「レビューエージェント」の3種類のエージェントが連携して、指定のテーマでブログ記事を執筆するシステムが解説されています(図1)。
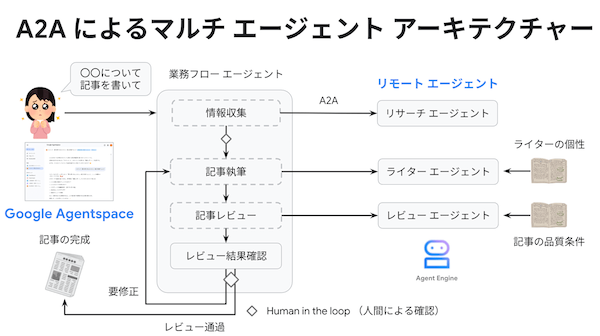
図1 マルチエージェントによるブログ記事執筆システム(ブログ記事より抜粋)
冒頭の論文では、可視化対象のデータとユーザーからの指示に従って、論文などに掲載するグラフを自動生成する仕組みをマルチエージェント・アーキテクチャーで実装した例が紹介されています。最近のLLMはプログラムコードを出力する機能を持っているので、単体のLLMを利用して、グラフを描画するコードを出力することもできますが、全体の作業を複数のエージェントに分解することで、より高品質なグラフが生成できます。
特に最近の研究では、エージェントの役割を複数のサブタスクに分解する際は、「理解(Understanding)」「計画(Planning)」「生成(Generation)」「自己反省(Self-Reflection)」の4つのフェーズに分けることで、エージェントシステム全体の性能が大きく向上することがわかってきました。この論文で解説している「CoDA(Collaborative Data-visualization Agents)」と呼ばれるシステムは、この考え方に従って、8種類のサブエージェントがこれら4つのフェーズに従って処理を行います(図2)。
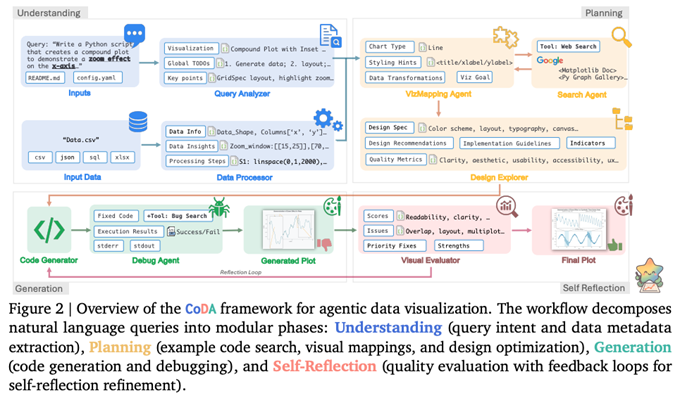
図2 CoDA のアーキテクチャー概要(論文より抜粋)
論文内では、CoDAとの比較対象として、既存の類似システム(MatplotAgent、VisPath、CoML4VIS)との性能比較を行っています。いずれのシステムも複数のサブエージェントが段階的に処理を進めるパイプライン型のシステムですが、前述の4つのフェーズに従う CoDA の方がより高い性能を発揮することが報告されています(図3)。
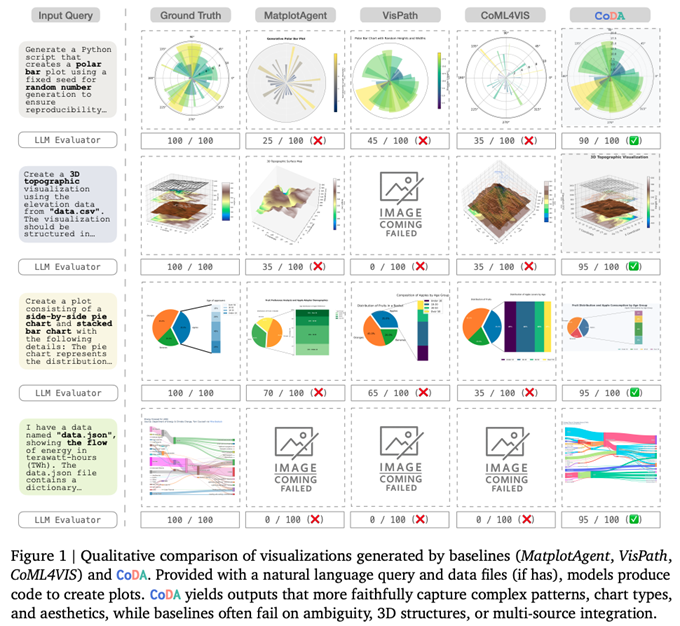
図3 既存の類似システムと CoDA の比較例(論文より抜粋)
CoDAを構成する8種類のサブエージェントの役割を説明します。まず、「理解(Understanding)」のフェーズは、次の2つのサブエージェントが担当します。
「計画(Planning)」のフェーズは、次の3つのサブエージェントが担当します。
「生成(Generation)」のフェーズは、次の2つのサブエージェントが担当します。
最後に「自己反省(Self-Reflection)」のフェーズは、次のサブエージェントが担当します。
最後のVisual Evaluatorは、生成されたグラフを受け入れるかどうかの判断を行い、受け入れできない場合は、Design Explorerに処理を戻して、グラフのデザインとコード生成をやり直します。最大で5回の処理を行い、生成した中で最も品質の高いグラフを最終成果物として出力します。
今回は、2025年に公開された論文「CoDA: Agentic Systems for Collaborative Data Visualization]」に基づいて、データの可視化処理をマルチエージェントで実行するアーキテクチャー「CoDA(Collaborative Data-visualization Agents)」について、マルチエージェントの考え方とCoDaのアーキテクチャーを説明しました。次回は、それぞれのサブエージェントの具体的な出力例を紹介していきます。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































