これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2025年に公開された論文「Wave: Offloading Resource Management to SmartNIC Cores」に基づいて、タスクスケジューラやメモリ管理の処理など、OSの管理タスクをSmartNICのCPUコアにオフロードするアーキテクチャー「Wave」について解説します。今回は、PCIeのレイテンシーの課題に対応する最適化技術、および、Waveの性能評価データを紹介します。
前回の記事で説明したように、MMIOを用いてホストからPCIe経由でSmartNIC上のメモリーを読み取る操作には、往復で約750ナノ秒という大きな遅延が発生します。マイクロ秒未満での意思決定が求められるシステム処理において、この遅延は無視できません。Waveは、このPCIeの遅延を隠蔽するために「キャッシュ」と「プリフェッチ(事前読み込み)」を組み合わせた最適化を実装しています。
次の図1は、WaveにおけるCPUキャッシュの利用形態を示します。SmartNIC上のCPUコアがSmartNIC上のメモリー(DRAM)にアクセスする際は、一般的な「Write-Back(WB)」方式のCPUキャッシュを使用します。次に、ホストCPUがSmartNIC上のメモリーにデータを書き込む際は、書き込み専用のバッファにデータを蓄積し、一定のタイミングでまとめて転送する「Write-Combine(WC)」方式を使用します。これにより、PCIe経由の転送による遅延を隠蔽します。
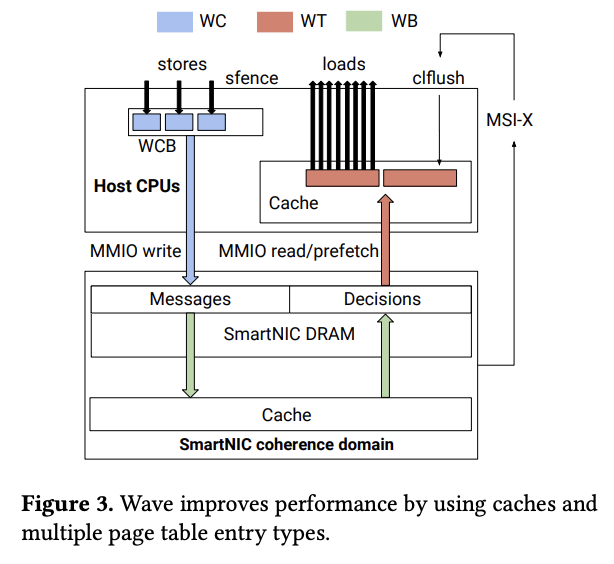
図1 WaveにおけるCPUキャッシュの利用(論文より抜粋)
そして、ホストCPUがSmartNIC上のデータを読み取る際は、ホスト側のメモリーのページテーブルエントリを「Write-Through(WT)」に設定します。これにより、ホストCPUが読み取ったデータは、ホスト側のCPUキャッシュに転送・保持されます。そのため、同じデータを複数回読み取る場合、2回目以降の読み込みは高速に行われます。さらに、ホストCPUは、該当のデータが実際に必要になる前に、あらかじめ、データの読み込みを実行(プリフェッチ)することで、1回目の読み込みで発生する遅延も擬似的に隠蔽してしまいます。なお、エージェントがメモリー上のデータを更新して、キャッシュ上のデータが古くなった際は、エージェントからホストへ割り込みによる通知が送信され、ホストCPUが古いキャッシュを破棄します。
また、メモリ管理など、連続的なデータ処理が発生するエージェントでは、ホストCPUが一部のデータ処理の依頼を開始した時点で、その先に依頼がくると予想されるデータ処理も先回りして実行して、その結果をメモリー上に事前配置(プレステージング)します。Waveでは、これらの仕組みを組み合わせることで、約1マイクロ秒の読み取り遅延を隠蔽し、ホストが必要な時には、データがすでに高速なキャッシュに存在している状態を作り出します。
ここでは、論文内で紹介されている、Waveの性能評価データを紹介します。まず、Waveを利用したタスクスケジューリングの有効性を示す例として、仮想マシン(VM)のスケジューリングの評価結果(図2)があります。
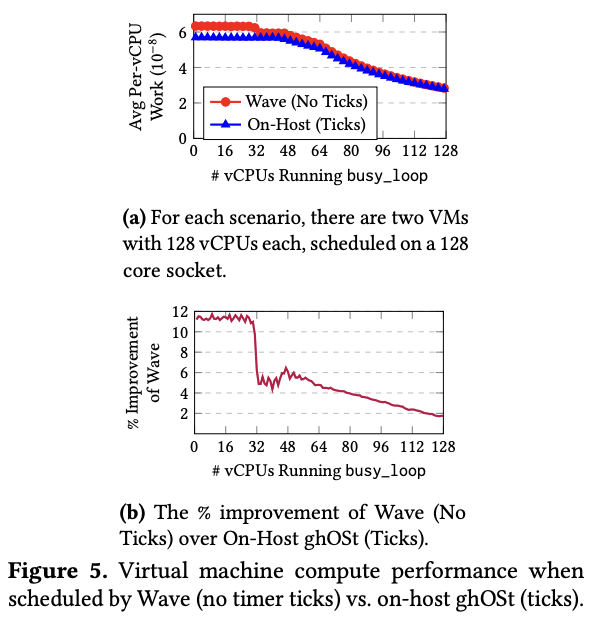
図2 Waveによるタスクスケジューラのオフロードの効果(論文より抜粋)
従来のホストCPUでのスケジューリングでは、特定のVMが長期間CPUコアを占有しない様に、すべてのコアに対して、1ミリ秒ごとにタイマー割り込みを発生させて、実行するVMを切り替えていました。このタイマー割り込みは、アイドル状態のコアに対しても発生するために、アイドル状態のコアがスリープモードに入らず、結果として、他の稼働中のコアがターボブーストの恩恵を得られないという課題がありました。Waveを用いてスケジュール機能をオフロードすると、ホストCPU側でのタイマー割り込みが不要になるので、この問題がなくなります。図2の上図をみると、Waveの方がvCPUあたりの処理能力が高くなっていることがわかります。特に、稼働中のCPUコアが少ない場合(言い換えると、アイドル状態のCPUコアが多い場合)にこの効果が高くなることが、図2の下図から読み取れます。稼働中のvCPUが1つの場合で11.2%の性能向上が得られています。また、全コアがフル稼働している場合でも、割り込み処理が減ったことで1.7%の性能向上が見られます。これは、サーバー1台あたり約4.4個分のホストコアを節約したことに相当します。
また、Waveは、計算負荷の高いタスクのオフロードにも効果を発揮します。論文内では、機械学習を用いてメモリのアクセス頻度を分析して、データを高速なDRAMと低速なストレージ間に最適配置する、「SOL」と呼ばれるメモリ管理ポリシーを評価しています。SOLは実メモリの消費量を大幅に削減できる強力なものですが、実用的な時間で処理を終えるには、最大で16個のCPUコアを計算専用に占有してしまいます。Waveを用いてこの機能をSmartNICのCPUコアにオフロードすることで、ホストのCPUコアを消費せずに、SOLを実現することに成功しています。論文内では、この他にもさまざまな評価データが紹介されていますので、興味のある方は、実際の論文も確認してみてください。
今回は、2025年に公開された論文「Wave: Offloading Resource Management to SmartNIC Cores」に基づいて、OSの管理タスクをSmartNICのCPUコアにオフロードするアーキテクチャー「Wave」について、PCIeのレイテンシーの課題に対応する最適化技術とWaveの性能評価データを紹介しました。
次回は、SmartNICをはじめとした複雑なコンポーネントを要するサーバーシステムの構成管理に関する話題をお届けします。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes































