
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2024年に公開された論文「Transparent Migration of Datastore to Firestore」を紹介します。この論文では、Cloud DatastoreからFirestoreへのデータマイグレーションについて、その舞台裏の技術が解説されています。これは、Google Cloudで利用されている100万インスタンスを超えるCloud Datastoreのデータベースを無停止で移行するという、大規模なデータマイグレーションの事例です。今回はまず、このデータマイグレーションが行われた背景と移行時の考慮点を説明します。
現在、Google Cloudでは、NoSQLデータベースサービスのFirestoreが提供されていますが、Firestoreを利用する際は、「Naitiveモード」と「Datastoreモード」の2種類のAPIが選択できます。Datastoreモードは、Firestoreに先行して提供されていたCloud Datastoreと互換のAPIを提供するもので、Cloud Datastoreの後継として利用できます。Firestoreの提供が開始されたのは2019年ですが、この時点では、旧来のCloud Datastoreを利用するユーザーと新しく導入された「DatastoreモードのFirestore」を利用するユーザーが混在する状況でした。この時、Firestoreの開発チームは、Cloud Datastoreの既存のデータベースをすべてFirestoreに移行して、旧来のCloud Datastoreのサービス提供を終了するという判断をしました。冒頭の論文によると、この決断の背景には、それぞれのデータベースのバックエンドにある技術の違いがありました。(これ以降では、「DatastoreモードのFirestore」を単純に「Firestore」と記述します。)
まず、Cloud Datastoreは、2008年にGoogle AppEngineのデータストアとして提供が開始されました。第7回の記事『スケーラビリティと一貫性を両立した分散データストアMegastore(パート1)』からの一連の記事で解説したように、Cloud Datastoreは、Google社内で利用されていたMegastoreというサービスを利用しており、Megastoreのバックエンドは、Bigtableになります。当時のBigtableは、複数のリージョンにデータをレプリケーションする機能が提供されておらず、Megastoreは、独自のReplication Serverによって、複数リージョンへのレプリケーションを実現していました。一方、第153回の記事『サーバーレスNoSQLデータベースサービス「Firestore」(パート1)』からの一連の記事で説明したように、Firestoreは、分散RDBのSpannerをバックエンドにしており、Spanner自身のレプリケーション機能が利用できるため、全体のアーキテクチャーがよりシンプルになります。また、Spannerは、強い整合性を持ったトランザクションが実行できるので、Firestore自身にも強い整合性を持たせることができます。
このように、Firestoreは、Cloud Datastoreに比べて、アーキテクチャーや提供機能の優位性があります。また、互換性のある2種類のサービスを同時に提供するのは、メンテナンスコストの観点からも得策とは言えません。これらの観点から、Cloud Datastoreの既存のデータベースをすべてFirestoreに移行する決定をしたそうです。
Firestoreは、Cloud Datastoreと互換のAPIを提供すると言っても、すべての動作が完全に一致するわけではありません。データベースを移行する際は、これらの違いに注意を払う必要があります。論文の中では、トランザクションの整合性に関する違いと、それに関連したパフォーマンスの違いが説明されています。
まず、Cloud Datastoreでは、一般には、結果整合性が提供されており、強い整合性を持ったトランザクションは、特定のクエリーに限定されます。一方、Firestoreでは、すべてのトランザクションに対して強い整合性が提供できます。結果整合性の場合、トランザクションによる変更結果が反映されるまで、ある程度の待ち時間が発生しますが、強い整合性の場合、トランザクションの結果は即座に反映されます。結果整合性における待ち時間が0になったと考えれば、結果整合性を前提としたアプリケーションを強い整合性の環境に移行しても、原理的には問題が起きないような気がします。しかしながら、強い整合性を持ったトランザクションは、一般に、そうでないトランザクションより処理時間が長くなります。Cloud DatastoreからFirestoreに移行することで、このような性能差の問題が起きる可能性があります。
また、強い整合性を提供する際のロック処理にも違いがあります。Cloud Datastoreは、読み取りの際に強い整合性を要求すると、楽観的ロックが使われます。これは、一連のデータを読み出した後に、読み取り中に該当のデータが変更されていないかをチェックして、変更されていた場合は、その読み取り処理をエラーで返します。一方、Firestoreの強い整合性は、バックエンドのSpannerの機能に依存しており、Spannerでは悲観的ロックが用いられます。これは、トランザクションの実行中は、他のクエリーによる該当部分のデータ変更が禁止されます。
論文によると、Cloud Datastoreのあるユーザーは、データのバックアップ処理に強い整合性を持った読み取り処理を利用していたそうです。バックアップ対象のデータを数分間に渡るトランザクションで読み込み、結果がエラーにならなければ、トランザクション開始時点の整合性のあるデータとしてバックアップ用のストレージに書き込みます。読み込み中にデータが更新された場合はトランザクションがエラーになるので、整合性のないデータを誤ってバックアップすることを防止できます。これをそのままFirestoreに移行するとどうなるでしょうか? トランザクションによるデータの読み込み中は、他のクエリーはデータの更新ができなくなるため、アプリケーションから見ると、数分間に渡って該当部分のデータの書き込みがブロックされます。これはアプリケーションとして許容できるものではありません。
このような問題を回避するために、Firestoreでは、トランザクションの同時実行モードとして、「悲観的」「楽観的」「エンティティグループによる楽観的」の3種類を提供しています。「悲観的」はSpanner本来の悲観的ロックを使用するもので、「楽観的」はDatastoreと同様の楽観的ロックを使用します。さらに、「エンティティグループによる楽観的」は、楽観的ロックに加えて、トランザクションに関わる細かな仕様を従来のDatastoreと完全に一致させます。Datastore独自のトランザクションの仕様に依存したアプリケーションでは、「エンティティグループによる楽観的」を選択します。
ここまで、トランザクションの仕組みの違いを説明しましたが、トランザクションの違いによる性能差についても対処する必要があります。Firestoreのバックエンドに使用するSpannerでは、割り当てるCPUやメモリを増やしてトランザクションの性能を向上させると同時に、新たに「index sharding」の機能を実装しました。これは、シーケンス番号のように連続する値をレコードの主キーとして用いた場合に発生する「index lasering」という問題に関連します。BigtableやSpannerでは、主キーの順番にデータが格納されるので、連続する値を主キーとしてデータを追記していくと、特定のノードに書き込み処理が集中して書き込み性能が極端に低下することがあります。Datastoreでは、このような利用方法は避けるようにガイドされていましたが、当然ながらすべてのユーザーがガイドに従っているとは限りません。強い整合性を提供するSpannerでは、index laseringによる性能低下がBigtableよりも大きくなる可能性があるため、Cloud Datastoreでは問題にならなかった性能低下が、Firebaseに移行後に問題になる恐れがあります。
そこで、Firebaseでは、index laseringが発生しているテーブルについては、バックエンドのSpannerにデータを格納する際に、主キーの先頭に追加の「shard ID」を加えることで、shard IDによる強制的な分散を行う仕組みを追加しました。図1は、実際のアプリケーションで発生したデータの書き込みを再現して、MegastoreとSpannerでの性能差をビジュアライズした結果です。横軸はMegastoreへの書き込み速度で、縦軸はSpannerへの書き込み速度に対応しており、図の左上はSpannerの方が遅い場合、右下はMegastoreの方が遅い場合になります。対応するデータが多い部分は強く光って表示されています。左の(a)図はshard IDを使用しない場合ですが、全体的にデータが縦に伸びており、Spannerの方が極端に遅いケースが含まれています。一方、右の(b)図はshard IDを使用する場合で、Spannerの処理性能が改善されていることがわかります。
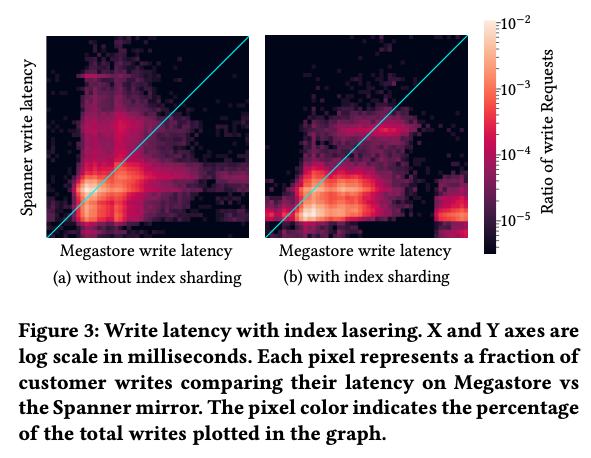
図1 index shardingの効果(論文より抜粋)
今回は、2024年に公開された論文「Transparent Migration of Datastore to Firestore」に基づいて、Cloud DatastoreからFirestoreへのデータマイグレーションについて、その背景と移行時の考慮点を説明しました。次回は、実際の移行方法を技術的な観点で説明します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































