
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2024年に公開された論文「Transparent Migration of Datastore to Firestore」を紹介します。この論文では、Cloud DatastoreからFirestoreへのデータマイグレーションについて、その舞台裏の技術が解説されています。今回は、実際の移行方法を技術的な観点で説明します。
前回の記事で説明したように、Cloud DatastoreとFirestoreは、バックエンドのデータストアがBigtableかSpannerかという大きな違いがありました。Cloud Datastoreのデータベースを無停止でFirestoreに移行するには、Bigtable上の既存のデータをSpannerに複製すると同時に、新しく書き込まれるデータをBigtableとSpannerの両方に書き込むというリアルタイムレプリケーションの処理が必要になります。図1は、これを実施するために用意された移行システムのアーキテクチャーの概要です。
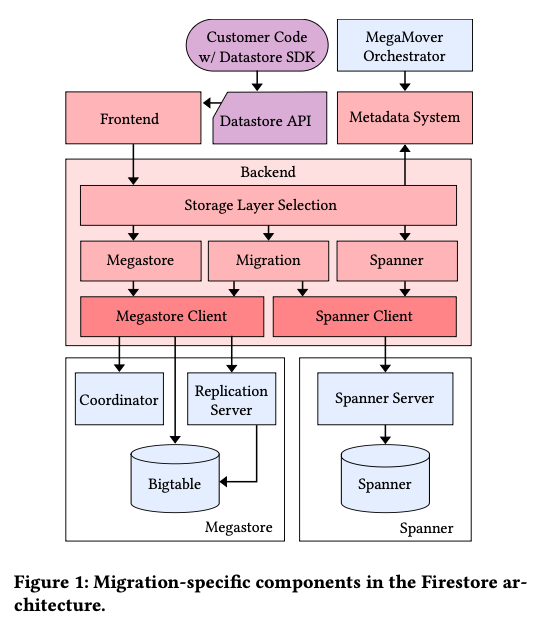
図1 データ移行システムのアーキテクチャー(論文より抜粋)
フロントエンドからデータの読み書きのリクエストを受けたバックエンドは、データ移行の段階に応じて、読み書きするバックエンド(MegastoreかSpanner)を選択して、さらに、リアルタイムレプリケーションの処理を実施します。移行の段階に応じた処理の違いは、論文内では、図2のようにまとめられています。
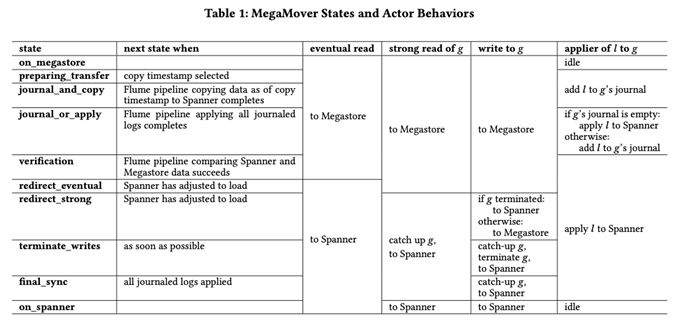
図2 データ移行の段階よる処理の違い(論文より抜粋)
図2に示した処理の段階を順番に説明します。まず、最初の3つの段階は次のようになります。
・on_megastore:移行開始前の状態(すべての処理をMegastoreだけで実行)
・preparing_transfer:データ複製のタイムスタンプを決定
・journal_and_copy:決定したタイムスタンプ以前のデータをSpannerにコピー。決定したタイムスタンプ以降の書き込みは、Megastoreに書き込むと同時に、書き込み内容のログをSpanner側のジャーナル情報として記録
ここまでは、Megastoreの既存のデータをSpannerに一括でコピーする段階に当たります。コピー中に発生した追加の書き込みは、Spanner側には即時反映できないため、書き込みログをジャーナル情報として記録しておきます。そして、データコピーが完了すると、ジャーナル情報を反映する次の段階へと移行します。
・journal_or_apply:ジャーナルに記録された書き込みログをSpannerのデータベースに反映
ジャーナルに記録されたログがすべて反映された後は、Megastoreへの書き込み情報のログは、ジャーナルを介さずに、Spannerに即時反映されます。ここまで来ると、データの読み書きはMegastore側で行いながら、Spannerにも同じデータが記録された状態が確保されます。ここで、念のために、それぞれのデータが一致していることを確認する処理を行います。
・verification:MegastoreのデータとSpannerのデータが一致していることを確認
この後は、データの読み込み処理を段階的にSpanner側に移行することで、Spannerのウォームアップ(アクセス量に応じたノードのスケールアウト)を行います。
・redirect_eventual:結果整合の読み込みをSpannerに移行
・redirect_strong:強整合の読み込み(トランザクション)をSpannerに移行
ここで、すべての読み込み処理がSpanner側で行われるようになります。ただし、書き込み処理については、Megastore側で行った上で、書き込みログをSpannerに転送して反映するという形は変わりません。この次の段階で、書き込み処理もSpanner側で直接実施するように変更します。
・terminate_writes:書き込み処理をSpanner側で実施
・final_sync:Megastoreに依存する処理がすべて完了していることを確認
・on_spanner:移行完了状態(すべての処理をSpannerで実行)
以上がMegastoreからSpannerへのデータ移行の流れになります。Cloud Datastoreの膨大な数のデータベースがMegastoreに保存されていますので、上記の処理は、複数のデータ区画にわけて行っていきます。実際の移行作業においては、データ量が少なく、長期間アイドル状態のデータベースから移行を行うなどの安全策も取られました。このような移行プロジェクトを進める上での工夫や、プロジェクトを通して得られた知見については、次回にあらためて解説します。
今回は、2024年に公開された論文「Transparent Migration of Datastore to Firestore」に基づいて、Cloud DatastoreからFirestoreへのデータマイグレーションについて、実際の移行方法を技術的な観点で説明しました。次回は、移行プロジェクトを通して得られた知見を紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































